Microsoft Cognitive サービスによる OCR 解析
マイクロソフトの Cognitive サービスには OCR (光学式文字認識:画像に含まれる文字列をテキストデータとして抽出) の機能があります。現在はプレビュー版としてこの機能が提供されています。
Cognitive Services : Computer Vision API – v1.0 OCR
● Java のサンプル・アプリケーションについて
JAX-RS Client API を使って、Java の OCR サンプルを作り下記に公開しました。ご興味ある方はお試しください。
https://github.com/yoshioterada/OCR-Sample-of-Cognitive-Service
※ 本プログラムをお試しいただくためには、Subscription ID を入手して頂く必要があります。コチラ(Cognitive Services Computer Vision)より「Get started for free」のボタンを押し「Computer Vision – Preview 5,000 transactions per month, 20 per minute. 」にチェックし「Subscribe」ボタンを押して「Subscription ID」を入手してください。入手した ID を、プログラム中の SUBSCRIPTION_ID に記載してください。
画像は、以下の3種類の方法で指定できます。
1. 画像が置かれている URI を指定
2. ローカル・ディレクトリを含む絶対パスでファイル名を指定
3. 画像の byte[] を指定
public class Main {
private final static String SUBSCRIPTION_ID = "*******************************************";
public static void main(String argv[]) {
OCRService service = new OCRService(SUBSCRIPTION_ID);
// GET the result of OCR from specified URI
String pictURI = "http://businessnetwork.jp/Portals/0/SP2016/PSTN/img/1604_microsoft_top.jpg";
Optional<OCRResponseJSONBody> result = service.getOCRAnalysisResult(pictURI);
result.ifPresent(resultBody -> service.printOCRResult(resultBody));
//GET the result of OCR from the local file
try {
Optional<OCRResponseJSONBody> result2 = service.getOCRAnalysisResult(Paths.get("/Users/terada/Downloads/aaa.jpeg"));
result2.ifPresent(resultBody -> service.printOCRResult(resultBody));
} catch (IOException ex) {
Logger.getLogger(Main.class.getName()).log(Level.SEVERE, null, ex);
}
}
}
下記に、本プログラムを利用した解析結果の例をご紹介します。
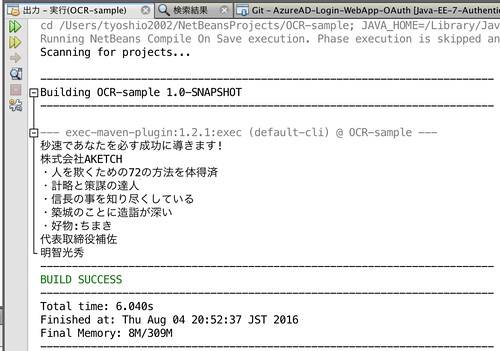
●解析結果例1
まず、解析結果として、とてもうまくいった例をご紹介します。例として、sansan さんのサンプル名刺を利用させていただきました。

解析したらこんな結果が得られました。完全に一致していますね!!
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
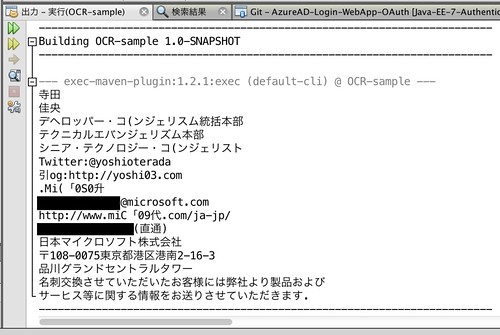
●解析結果例2
次に私の名刺を解析しました(メールと電話番号だけ伏せさせてください)。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
その結果、こうなりました。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
「Microsoft」が「Mi(「0S0升」、「Blog」が「引log」になっています。どうやら、現時点で日本語と英語がまざると、日本語解析が英語解析より優先度強くはたらき、ローマ字に似た日本語の文字を当てはめるみたいです。例えば「@yoshioterada」が「yoshiote「ada」と解析された場合もあります。
●日英がまざる場合の現時点の回避策
現時点では(ワークアラウンドとして)、日本語解析と英語解析を2度実行し有効な文字列を抽出するのが良いのではないかと思っています。
実際に、OCR 処理用の REST URL は下記になります。
https://api.projectoxford.ai/vision/v1.0/ocr?language=en&detectOrientation=true”
ここで引数に language を指定しますが、language=en,language=ja で、それぞれ英語か日本語の解析を切り替えます。日英両方を含む場合、現時点のワークアラウンドとして、”en” と “ja” の2回解析し、取得結果から意味的に有効な方を使うというのも良いかもしれません。
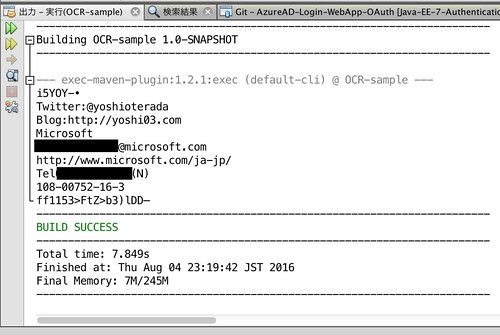
実際に、language=en を指定し、英語解析で名刺を解析させると、下記のように「Mi(「0S0升」と解析されていた箇所も正しく「Microsoft」と、そして「Blog」も正しく解析できていました。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
REST の呼び出し結果(JSON)を確認すると1文字ずつ文字を抽出し認識しているようです。1行単位(つまり文字の前後関係)では解析はしていないので、1行を抜き出し本当に意味のある正しい文字列になっているかどうかを判定するような処理を入れれば精度はあがるのではないかと思います。(例えば「Mi(「0S0升」や「引log」のように1行中に1バイト文字と2バイト文字が混合しているなどはおかしい可能性が高いです。あと o(オー) と 0(ゼロ) も間違える場合があります。さらに l(エル), I(大文字のアイ), 1(イチ)も同様です。 怪しい場合には Bing の検索 API で探すという手もありかもしれません。)
こちらについては、Java に限らずどの言語を利用しても同じ結果が得られると想定しますので、本国の開発チームには多言語対応への課題としてフィードバックしたいと思っています。
まだプレビュー版ですが、1月辺り 5,000 処理、もしくは1分間辺り 20 処理までは無料でご利用いただけます。どうぞお試し版(プレビュー)としてご利用ください。
Entry filed under: Java, Microsoft Azure. Tags: Cognitive Service, JAX-RS, OCR, REST.


