Posts tagged ‘Java’
leJOS + NetBeans 8.0 (Maven) + Java SE Embedded (7 or 8) で LEGO Mindstorms EV3のアプリケーション開発
今日は Java の開発者の皆様に、LEGO Mindstorms EV3 の制御を Java で行うために、環境構築から NetBeans を使用した Java のアプリケーションの開発方法までをご紹介します。LEGO 社は、幅広い年代の子供達に向けて LEGO ブロックを提供しています。最近では私の2歳になる子供も LEGO duplo という幼児向けのレゴで遊んでいます。
今日、ご紹介する「教育版レゴ マインドストームEV3」 は、LEGO Mindstorms を教育目的で使うために開発された製品で、これを使用するとブロックでロボットを作成した後、Java でそのロボットを制御する事もできるようになります。今回、Java でロボット制御を試すために、「教育版レゴ マインドストームEV3 / LEGO Mindstorms Eduation EV3 」の日本の正規代理店である(株)アフレル様のご協力を得て、LEGO Mindstorm を1台お借りし、実際に教育版レゴ マインドストームEV3 用の Java アプリケーションを書いてみました。
● アプリケーションの動作イメージ:
今回、作成した LEGO Mindstorms EV3 のサンプル・アプリケーションのソースコードは GitHub にアップしていますので、ご興味のある方はどうぞご覧ください。
https://github.com/yoshioterada/Java-Sample-app-for-LEGO-Mindstorms
本エントリでは、上記のサンプル・アプリケーションの実装に対する詳細の説明ではなく、Java でプログラムを書く事ができるように環境構築から最初のプログラム作成の部分までをご紹介します。
事前準備:
(1) レゴマインドストーム EV3 の入手
LEGO Mindstorms は 教育版と玩具版があり含まれる内容が異なります。
参考:教育版と玩具版の比較 (アフレル)
教育版
「教育版レゴ マインドストームEV3」の入手 (本エントリではこちらを使用)
販売先情報 :アフレル(株)


玩具版: Amazon 等から
レゴ マインドストーム EV3 31313(¥51,000)
レゴ マインドストーム EV3 31313 LEGO Mindstorms EV3 並行輸入品(¥ 44,320)
LEGO Mindstorms EV3 31313($349.95)
玩具版の レゴも Amazon で $350 〜 ¥51,000と少々高価な商品ですが、対象年齢は 10 歳以上のれっきとした LEGO です。機能的にこれは本当に子供向けなのか?!と思う程、自分でロボットを組み立てたり、そのロボットを制御するプログラムを書けたりと、子供よりも大人が熱中しそうな商品です。今回のエントリは玩具版でもご参考いただけるかと思います。
(2) USB WiFi アダプタの入手
USB の WiFi アダプタは EV3 に標準で付属していませんがあった方がとても便利です。開発時、開発環境から EV3 へネットワークを通じてアプリケーションをデプロイしたり、リモートから EV3 を制御したい場合、WiFi アダプタが必要です。今回、(株)アフレル様のご好意で「Roland Wireless USB Adapter WNA1100-RL」も借りる事ができたため、私はこの WiFi アダプタを使用します。Amazon から WNA1100-RL を購入していただく事も可能です。

その他、EV3 では下記の WiFi の USB アダプタが動作確認されています。特に EDIMAX EW-7811Un は EV3 からあまり突出しないのでオススメです。
動作確認済みの WiFi アダプタ
(3) leJOS 0.8.1 beta の入手

leJOS は LEGO Mindstorms EV3 のファームウェアを変更した OS で、この環境上で Java SE 7 Embedded 7 が稼働し、Java のアプリケーションを動かす事ができるようになります。
leJOS EV3 0.8.1 beta release より leJOS_EV3_0.8.1-beta.tar.gz を入手してください。
(4) Oracle Java SE Embedded の入手
Java for LEGO® Mindstorms® EV3 のサイト(オリジナルJRE入手先)から、Oracle Java SE Embedded を入手してください。
Java SE Embedded 7 の場合:
● ejre-7u55-fcs-b13-linux-arm-sflt-headless-17_mar_2014.tar.gz
Java SE Embedded 8 のインストール方法は、本エントリの最後に記載しています。
(5) 開発環境用 (Mac/Linux/Windows環境) に統合開発環境、Java SE をインストール
デスクトップの開発環境に NetBeans 8 と Java SE 7 をインストールしてください。(今回は各インストール方法の詳細は割愛)
● NetBeans の入手はこちらから
● Java SE 7 の入手はこちらから

leJOS 環境構築から開発までの手順
LEGO Mindstorms EV3 で Java アプリケーションを動作させるためには、下記の手順に従って行います。
- ブート可能なマイクロ SD カードへ leJOS のインストール
- ブート可能なマイクロ SD カードから起動
- leJOS で WiFi 設定
- ローカル Maven レポジトリに必要ライブラリをインストール
- Maven プロジェクトの作成
- アプリケーションの開発
- アプリケーションのビルド/デプロイ
- アプリケーションの実行
(0)ブート可能なマイクロ SD カードを作成
ブート可能で FAT 32 でフォーマットしたマイクロ SD カードを作成してください。Mac OS/X の場合、「アプリケーション」→「ユーティリティ」→「ディスクユーティリティ」を実行して作成できます。「パーティションのレイアウト」から「1パーティション」を選択し、「パーティション情報」に「名前」を記入してください。
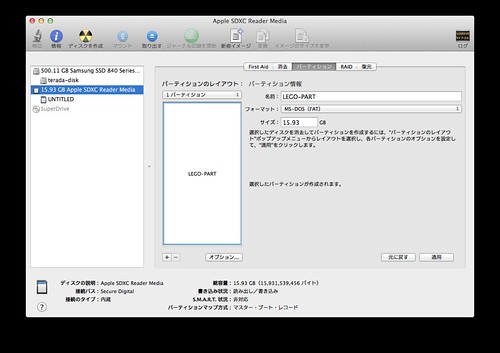
次に「オプション…」ボタンを押下してください、すると下記のウィンドウが表示されます。ここで、「マスター・ブート・レコード」にチェックされている事を確認し「OK」ボタンを押下してください。

最後に「適用」ボタンを押下してください、押下すると下記の画面が表示されます。ここで「パーティション」ボタンを押下してください。

(1) SD カードへファイルのコピーと展開 (Mac/Linux/Windows 環境で実施)
事前準備の (3) でダウンロードした leJOS_EV3_0.8.1-beta.tar.gz を展開してください。
| > tar xvf leJOS_EV3_0.8.1-beta.tar.gz > ls COPYING README.md bin lejosimage.zip lib samples.zip sd500.zip |
展開すると lejosimage.zip が存在しますので、このファイルと JRE7 を SD にコピーしてください。ファイルをコピーした後、SD カード内で lejosimage.zip を展開してください (※ JRE の展開は不要です)。
| > cp ejre-7u55-fcs-b13-linux-arm-sflt-headless-17_mar_2014.tar.gz lejosimage.zip /Volumes/LEGO-PART/ > cd /Volumes/LEGO-PART/ > unzip lejosimage.zip Archive: lejosimage.zip creating: lejos/ creating: lejos/bin/ inflating: lejos/bin/partition.sh inflating: lejos/bin/partfuncs.sh inflating: lejos/bin/install.sh inflating: lejos/bin/funcs.sh inflating: lejos/bin/spinner.sh inflating: lejos/bin/check.sh creating: lejos/images/ inflating: lejos/images/lejoslogo.ev3i inflating: lejosimage.bz2 inflating: uImage inflating: uImageStandard extracting: version # 展開した後の SD カードのディレクトリ構成 |
以上で準備は完了です。マイクロ SD カードをアンマウントして、システムから取り出してください。

取り出した後、EV3 にマイクロ SD カードを挿入してください。またその際、WiFi の USB アダプタも USB ポートに挿入してください。
(2)ブート可能なマイクロ SD カードから起動(EV3 で実施)
LEGO MindStorm に SD カードが挿入されている事を確認し、EV3 のボタンを押して起動してください。すると自動的に Linux 環境の構築(ファイルシステム構築等も含む)やJava 環境の構築を実施します。 (作業終了まで:約 8 分)
内部的には下記の処理等が行われています。
1. Resize FAT32 fs
2. Resize Complete
3. Create Linux fs
4. Expand Image
5. Prepare Install
6. Deleting old files
7. Expand Image
8. Start Install
9. Installing rootfs
10. Installing modules
11. Installing leJOS
12. Configure network
13. Install links
14. Install lib jna
15. Copy config files
16. Install jre
17. Extracting jre
18. Optimize java
19. Remove temp files
20. Installing kernel
21. Sync disks
22. Unmount disks
23. Rebooting
EV 3 はインストールや設定が完了すると自動的に再起動します。正常に起動が完了すると大きなブザー音が鳴った後、leJOS のメニュー画面が表示されます。


(3) leJOS で WiFi 設定(EV3 で実施)
WiFi の設定は、 WiFi の設定マークを選択して行います。選択すると接続可能なアクセス・ポイントの一覧が表示されます。
WiFi の設定マークを選択して行います。選択すると接続可能なアクセス・ポイントの一覧が表示されます。

自身の適切なアクセス・ポイントを選択してください。選択すると下記の画面が出てきます。

ここで、アクセス・ポイントに接続するため WEP のパスワードを入力します。基本的にはキーボード配列と同様にローマ字が並んでいますので、適切なパスワード文字を入力してください。ここで画面の一番最下行に特別な命令用の文字 (U,l,x,D) が記載されています、それぞれの意味は下記の通りです。大文字のローマ字を入力したい場合は、U を押す等してパスワードを正しく入力してください。
U : 大文字に変換 (Upper)
l : 小文字に変換 (lower)
x : 1文字消去
D : 設定終了 (Done)
パスワードを正しく入力した後、D を押下すると WiFi での接続ができるようになります。EV3 のメニュー画面で、IP アドレス: 10.0.1.1 と記載された行の下側に、割り当てられた IP アドレス(ここでは 192.168.1.100)が記載されていますので、この IP アドレスで EV 3 に接続できるようになります。EV3 に接続できるようになっているかどうかを確認するために、TELNET でログインをして確認してください。
| > telnet 192.168.1.100 Trying 192.168.1.100… Connected to 192.168.1.100. Escape character is ‘^]’. _____ _ _ ___ Rudolf 2011.01 EV3 login: root |
正常に、WiFi の設定ができている場合、上記のようなログイン・プロンプトが表示されます。ここで login: 名に root を、パスワードは未入力(ノンパスワード)でエンター・キーを押下してください。すると EV3 にログインができるようになります。
(4) ローカル Maven レポジトリに必要ライブラリをインストール (Mac/Linux/Windows 環境で実施)
今回、統合開発環境には NetBeans を使用し、Maven プロジェクトとしてアプリケーション開発を行います。EV3 を制御する Java アプリケーション開発を行うためには、ev3classes.jar と dbusjava.jar が必要ですが、現在 leJOS 用の Maven レポジトリが存在していないようです。そこで、これら2つのファイルをローカルの Maven レポジトリにインストールしてください。2つのファイルは leJOS_EV3_0.8.1-beta.tar.gz を展開したディレクトリ内に含まれています。
| > cd leJOS_EV3_0.8.1-beta/lib/ev3 > ls dbusjava-src.zip dbusjava.jar ev3classes-src.zip ev3classes.jar |
次に、2つのファイルを mvn コマンドでローカル・レポジトリにインストールします。下記の 2 つのコマンドを実行してください。仮に mvn コマンドが自身の実行パス内に見つからない場合は、NetBeans 付属のmvn コマンドをご利用ください。
例:Mac OS/X (Linux) の場合 mvn はデフォルトで下記に存在します。
“/Applications/NetBeans/NetBeans 8.0.app/Contents/Resources/NetBeans/java/maven/bin/mvn”
| > mvn install:install-file -Dfile=ev3classes.jar -DgroupId=ev3.classes -DartifactId=ev3classes -Dversion=0.8.1 -Dpackaging=jar [INFO] Scanning for projects… [INFO] [INFO] ———————————————————————— [INFO] Building Maven Stub Project (No POM) 1 [INFO] ———————————————————————— [INFO] [INFO] — maven-install-plugin:2.3.1:install-file (default-cli) @ standalone-pom — [INFO] Installing /Users/USER_NAME/Downloads/leJOS_EV3_0.8.1-beta/lib/ev3/ev3classes.jar to /Users/USER_NAME/.m2/repository/ev3/classes/ev3classes/0.8.1/ev3classes-0.8.1.jar [INFO] Installing /var/folders/5x/qqvk50_50xl7jvfhyf9_tdd40000gn/T/mvninstall6910985062740456417.pom to /Users/USER_NAME/.m2/repository/ev3/classes/ev3classes/0.8.1/ev3classes-0.8.1.pom [INFO] ———————————————————————— [INFO] BUILD SUCCESS [INFO] ———————————————————————— [INFO] Total time: 0.623s [INFO] Finished at: Tue Apr 22 20:22:57 WIT 2014 [INFO] Final Memory: 5M/245M [INFO] ———————————————————————— > mvn install:install-file -Dfile=dbusjava.jar -DgroupId=ev3.dbus -DartifactId=dbusjava -Dversion=0.8.1 -Dpackaging=jar |
例:Windows の場合 mvn はデフォルトで下記に存在します。
C:\Program Files\NetBeans 8.0\java\maven\bin
Windows で mvn コマンドをターミナルから実行するために、下記2つの環境変数の設定を行ってください。
● JAVA_HOME を新規追加 : JDK をインストールした場所
● PATH へ追加 : maven コマンドへのパスの追加

上記、環境変数の設定を行った後、lib\ev3 ディレクトリに移動し下記のコマンドを実行してください。※ 大文字、小文字の打ち間違いにご注意ください。
| C:\Users\USER_NAME\Desktop\leJOS_EV3_0.8.1-beta_win32\lib\ev3 > mvn install:install-file -Dfile=dbusjava.jar -DgroupId=ev3.dbus -DartifactId=dbusjava -Dversion=0.8.1 -Dpackaging=jar [INFO] Scanning for projects… [INFO] [INFO] ———————————————————————— [INFO] Building Maven Stub Project (No POM) 1 [INFO] ———————————————————————— [INFO] [INFO] — maven-install-plugin:2.3.1:install-file (default-cli) @ standalone-po m — [INFO] Installing C:\Users\USER_NAME\Desktop\leJOS_EV3_0.8.1-beta_win32\lib\ev3\db usjava.jar to C:\Users\USER_NAME\.m2\repository\ev3\dbus\dbusjava.8.1\dbusjava-0 .8.1.jar [INFO] Installing C:\Users\USER_NAME\AppData\Local\Temp\mvninstall1908329777283214 622.pom to C:\Users\USER_NAME\.m2\repository\ev3\dbus\dbusjava.8.1\dbusjava-0.8. 1.pom [INFO] ———————————————————————— [INFO] BUILD SUCCESS [INFO] ———————————————————————— [INFO] Total time: 0.760s [INFO] Finished at: Thu Apr 24 19:29:44 JST 2014 [INFO] Final Memory: 5M/155M [INFO] ———————————————————————— C:\Users\USER_NAME\Desktop\leJOS_EV3_0.8.1-beta_win32\lib\ev3> mvn install:install- file -Dfile=ev3classes.jar -DgroupId=ev3.classes -DartifactId=ev3classes -Dversion=0.8.1 -Dpackaging=jar [INFO] Scanning for projects… [INFO] [INFO] ———————————————————————— [INFO] Building Maven Stub Project (No POM) 1 [INFO] ———————————————————————— [INFO] [INFO] — maven-install-plugin:2.3.1:install-file (default-cli) @ standalone-po m — [INFO] Installing C:\Users\USER_NAME\Desktop\leJOS_EV3_0.8.1-beta_win32\lib\ev3\ev 3classes.jar to C:\Users\USER_NAME\.m2\repository\ev3\classes\ev3classes.8.1\ev3 classes-0.8.1.jar [INFO] Installing C:\Users\USER_NAME\AppData\Local\Temp\mvninstall2687157046215461 183.pom to C:\Users\USER_NAME\.m2\repository\ev3\classes\ev3classes.8.1\ev3class es-0.8.1.pom [INFO] ———————————————————————— [INFO] BUILD SUCCESS [INFO] ———————————————————————— [INFO] Total time: 0.712s [INFO] Finished at: Thu Apr 24 19:31:49 JST 2014 [INFO] Final Memory: 5M/158M [INFO] ———————————————————————— |
(5) Maven プロジェクトの作成 (Mac/Linux/Windows 環境で実施)
NetBeans のメニューからプロジェクトを作成してください。まず、「ファイル(F)」→「新規プロジェクト(W)…」を選択してください。
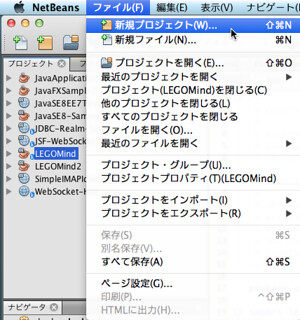
選択すると下記の「新規プロジェクト」作成用のウィンドウが表示されます。ここで、「カテゴリ (C) :」から「Maven」を選択し、「プロジェクト (P) :」から「Javaアプリケーション」を選択し「次へ」ボタンを押下してください。

ボタンを押下すると下記の「新規 Java アプリケーション」ウィンドウが表示されます。ここで「プロジェクト名 (N) :」、「プロジェクトの場所 (L) :」、「グループ ID (G) :」、「バージョン (V) :」、「パッケージ (P) :」に適切な値を入力した後、最後に「終了 (F)」ボタンを押下してください。
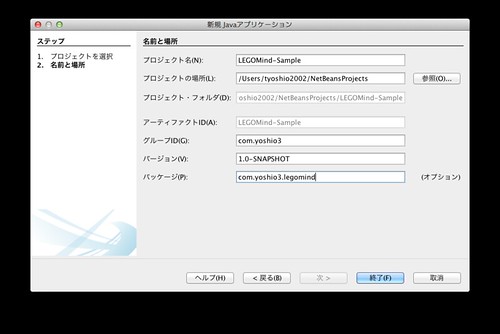
プロジェクトが正常に作成されるとプロジェクト・タブに下記のようなプロジェクトが作成されます。

プロジェクトを作成した後、pom.xml ファイルに下記を記載してください。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.yoshio3</groupId>
<artifactId>LEGOMind</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
<build>
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>1.0</version>
</extension>
</extensions>
<plugins>
<!--- MANIFEST ファイルを作成するプラグイン -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<mainClass>com.yoshio3.legomind.EV3AppMain</mainClass>
</manifest>
<manifestEntries>
<Class-Path>/home/root/lejos/lib/ev3classes.jar /home/root/lejos/libjna/usr/share/java/jna.jar</Class-Path>
</manifestEntries>
</archive>
</configuration>
</plugin>
<!--- デスクトップからネット経由で jar ファイルをコピーするためのプラグイン -->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0-beta-5</version>
<executions>
<execution>
<id>upload-jar</id>
<phase>package</phase>
<goals>
<goal>upload</goal>
</goals>
<configuration>
<!-- ~/.m2/settings.xml ファイルに記述したログインID、パスワードの参照 -->
<serverId>ev3-root</serverId>
<!-- EV3 に割り当てられている IP アドレス -->
<url>scp://192.168.1.100/</url>
<fromDir>${project.basedir}/target</fromDir>
<includes>*.jar</includes>
<excludes>*-sources.jar</excludes>
<!-- EV3 のコピー先ディレクトリ -->
<toDir>/home/lejos/programs</toDir>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<!-- ローカル・レポジトリにインストールしたファイルへの参照
mvn install:install-file
-Dfile=ev3classes.jar
-DgroupId=ev3.classes
-DartifactId=ev3classes
-Dversion=0.8.1 -Dpackaging=jar
-->
<dependencies>
<dependency>
<groupId>ev3.classes</groupId>
<artifactId>ev3classes</artifactId>
<version>0.8.1</version>
</dependency>
<!-- ローカル・レポジトリにインストールしたファイルへの参照
mvn install:install-file
-Dfile=dbusjava.jar
-DgroupId=ev3.dbus
-DartifactId=dbusjava
-Dversion=0.8.1
-Dpackaging=jar
-->
<dependency>
<groupId>ev3.dbus</groupId>
<artifactId>dbusjava</artifactId>
<version>0.8.1</version>
</dependency>
</dependencies>
</project>
また、Maven の設定ファイル ( ~/.m2/settings.xml (Windows では C:\Users\USER_NAME\.m2)) に下記を記載してください。
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<servers>
<server>
<id>ev3-root</id>
<!---- EV3 の root ログイン ID -->
<username>root</username>
<!---- EV3 の root ログイン パスワード -->
<password>password</password>
</server>
</servers>
</settings>
※ ご注意
pom.xml ファイルを設定、保存後に wagon のライブラリが存在しないため、下記のようにプロジェクトが「ロード不可能」と表示されます。

この場合、プロジェクトを右クリックし、「プロジェクトの問題を解決…」を選択してください(Maven のセントラルレポジトリよりライブラリを入手)。
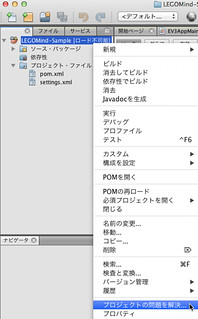
選択すると下記のウィンドウが表示されます。ここで「解決 (R) …」ボタンを押下してください。

(6) アプリケーションの開発(Mac/Linux/Windows 環境で実施)
Maven プロジェクトを作成したので実際にプログラムを初めてみましょう。今回は上記 pom.xml の MANIFEST ファイルの定義 <manifest> の <mainClass> タグ内でメイン・クラスとしてcom.yoshio3.legomind.EV3AppMain を定義しましたので、このクラスを作成します。また、初めての LEGO Mindstorms のアプリケーション開発ということで、やはり Hello World から初めてみましょう。プロジェクトの中に含まれる「com.yoshio3.legomind」パッケージを右クリックし「新規」→「Java クラス …」を選択してください。

選択すると下記のウィンドウが表示されます。ここで「クラス名 (N) :」に「EV3AppMain」と入力し「終了 (F)」ボタンを押下してください。

クラスを作成すると下記の画面が表示されます。
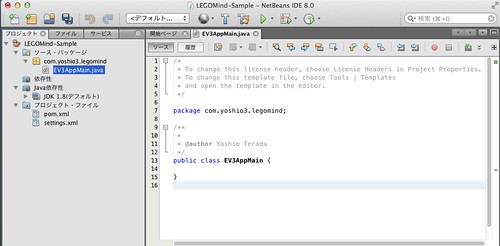
ここで、「EV3AppMain」クラスに対して、EV 3 のパネルに文字列を表示させ、3 秒程緑色の LED を点滅させるプログラムを下記のように記載します。
package com.yoshio3.legomind;
import lejos.hardware.Button;
import lejos.hardware.lcd.LCD;
import lejos.utility.Delay;
/**
*
* @author Yoshio Terada
*/
public class EV3AppMain {
public static void main(String... argv) {
//パネルに文字列を表示
LCD.drawString("Hello World", 0, 0);
//緑の点滅ボタンを3秒間光らせる(有効値: 0 - 9)
Button.LEDPattern(4);
Delay.msDelay(3000);
}
}
(7) アプリケーションのビルド/デプロイ(Mac/Linux/Windows 環境で実施)
コードを実装した後、プロジェクトをビルドしてください。プロジェクト・タブから「LEGOMind-Sample」プロジェクトを右クリックし「ビルド」を選択してください。

ビルドを行うと下記のメッセージが表示され、org.codehaus.mojo の wagon-maven-plugin を通じて、WiFi のネットワーク経由で自動的に /home/lejos/programs ディレクトリ配下に LEGOMind-1.0-SNAPSHOT.jar ファイルが配備されます。
cd /Users/USER_NAME/NetBeansProjects/LEGOMind; JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0.jdk/Contents/Home "/Applications/NetBeans/NetBeans 8.0.app/Contents/Resources/NetBeans/java/maven/bin/mvn" install Scanning for projects... ------------------------------------------------------------------------ Building LEGOMind 1.0-SNAPSHOT ------------------------------------------------------------------------ --- maven-resources-plugin:2.5:resources (default-resources) @ LEGOMind --- [debug] execute contextualize Using 'UTF-8' encoding to copy filtered resources. skip non existing resourceDirectory /Users/USER_NAME/NetBeansProjects/LEGOMind/src/main/resources --- maven-compiler-plugin:2.3.2:compile (default-compile) @ LEGOMind --- Nothing to compile - all classes are up to date --- maven-resources-plugin:2.5:testResources (default-testResources) @ LEGOMind --- [debug] execute contextualize Using 'UTF-8' encoding to copy filtered resources. skip non existing resourceDirectory /Users/USER_NAME/NetBeansProjects/LEGOMind/src/test/resources --- maven-compiler-plugin:2.3.2:testCompile (default-testCompile) @ LEGOMind --- No sources to compile --- maven-surefire-plugin:2.10:test (default-test) @ LEGOMind --- Surefire report directory: /Users/USER_NAME/NetBeansProjects/LEGOMind/target/surefire-reports ------------------------------------------------------- T E S T S ------------------------------------------------------- Results : Tests run: 0, Failures: 0, Errors: 0, Skipped: 0 --- maven-jar-plugin:2.4:jar (default-jar) @ LEGOMind --- Building jar: /Users/USER_NAME/NetBeansProjects/LEGOMind/target/LEGOMind-1.0-SNAPSHOT.jar --- wagon-maven-plugin:1.0-beta-5:upload (upload-jar) @ LEGOMind --- Uploading /Users/USER_NAME/NetBeansProjects/LEGOMind/target/LEGOMind-1.0-SNAPSHOT.jar to scp://192.168.1.100///home/lejos/programs/LEGOMind-1.0-SNAPSHOT.jar ... --- maven-install-plugin:2.3.1:install (default-install) @ LEGOMind --- Installing /Users/USER_NAME/NetBeansProjects/LEGOMind/target/LEGOMind-1.0-SNAPSHOT.jar to /Users/USER_NAME/.m2/repository/com/yoshio3/LEGOMind/1.0-SNAPSHOT/LEGOMind-1.0-SNAPSHOT.jar Installing /Users/USER_NAME/NetBeansProjects/LEGOMind/pom.xml to /Users/USER_NAME/.m2/repository/com/yoshio3/LEGOMind/1.0-SNAPSHOT/LEGOMind-1.0-SNAPSHOT.pom ------------------------------------------------------------------------ BUILD SUCCESS ------------------------------------------------------------------------ Total time: 4.837s Finished at: Tue Apr 22 21:09:27 WIT 2014 Final Memory: 11M/312M ------------------------------------------------------------------------
8. アプリケーションの実行(EV3 で実施)
leJOS のメニュー画面より Programs (/home/lejos/programs ディレクトリ)を選択してください。

選択するとデプロイされているファイル一覧が表示されますので、LEGOMind-1.0-SNAPSHOT.jar を選択してください。

選択すると下記の画面が表示されます。そのままエンター・キー(真ん中のボタン)を押下してください。

押下すると下記の Duke が手を振っている画面 (しばらくお待ちください) が表示されます。アプリケーションをロードするまで数秒かかりますのでそのままお待ちください。

アプリケーションがロードされると下記のように実行され、メニューに「Hello World」が表示され、ボタンの LED が緑色に点滅する事を確認できます。

9. LEGO を組み立てて、超音波センサー、タッチ・センサー、モータ(車輪)を取り付けます。
上記で、Java を使って LEGO Mindstorms を制御できる事がわかりました。後は EV3 に LEGO のパーツを組み立てて、超音波センサーやタッチ・センサー、モータ(車輪)などを取り付けて自分オリジナルのロボットを組み立ててみてください。

その後で、下記 GitHub にアップロードしているコード例をご参照いただき実装すると、センサーから受け取った情報を元に EV3 を制御できるようになります。
GitHub にアップしたサンプルは、タッチセンサーに何かがぶつかると車輪が逆方向に回転し、超音波センサーに物を近づけると車輪の回転スピードが遅くなります。最後に EV3 の何らかのボタンを押すとアプリケーションを終了します。
https://github.com/yoshioterada/Java-Sample-app-for-LEGO-Mindstorms
今回私の上記実装では、車輪毎にリスナーを登録しセンサーからの情報に応じて車輪を制御する方法で実装しましたが、leJOS で提供されているサンプルを確認すると、様々な方法で実装ができるようです。是非色々お試しください。
また、調べていてちょっとおもしろかったのが、上記のようにデプロイしなくても、デスクトップの Java アプリケーションからWiFi 経由 (RMI) でリモートのEV3 を制御する事ができるので、これと JavaFX や WebSocket と組み合わせて応用すればスマートフォンや他のデバイスからリアルタイムに EV3 を制御できるようになるのではないかと想定します。
package com.yoshio3.legomind;
import java.net.MalformedURLException;
import java.rmi.NotBoundException;
import java.rmi.RemoteException;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.logging.Level;
import java.util.logging.Logger;
import lejos.remote.ev3.RMIRegulatedMotor;
import lejos.remote.ev3.RMISampleProvider;
import lejos.remote.ev3.RemoteEV3;
import lejos.robotics.RegulatedMotor;
import lejos.robotics.RegulatedMotorListener;
/**
*
* @author Yoshio Terada
*/
public class RemoteOperation {
public static void main(String... argv) {
RemoteEV3 ev3;
try {
ev3 = new RemoteEV3("192.168.1.100");
RMISampleProvider sampleProv = ev3.createSampleProvider("S1", "lejos.hardware.sensor.EV3TouchSensor", "sensor");
// 車輪の制御
RMIRegulatedMotor right = ev3.createRegulatedMotor("B", 'L');
RMIRegulatedMotor left = ev3.createRegulatedMotor("C", 'L');
right.resetTachoCount();
left.resetTachoCount();
ExecutorService execSvc = Executors.newFixedThreadPool(3);
execSvc.submit(new RunMotor(right));
execSvc.submit(new RunMotor(left));
Future<Float> res = execSvc.submit(new MonitoringTouch(sampleProv));
if (res.get() == 1.0f) {
right.stop(true);
left.stop(true);
}
} catch (RemoteException | MalformedURLException | NotBoundException | InterruptedException | ExecutionException ex) {
Logger.getLogger(RemoteOperation.class.getName()).log(Level.SEVERE, null, ex);
}
}
}
class RunMotor implements Runnable {
RMIRegulatedMotor motor;
RunMotor(RMIRegulatedMotor motor) {
this.motor = motor;
}
@Override
public void run() {
try {
motor.setSpeed(400);
motor.rotate(360 * 20);
motor.close();
} catch (RemoteException ex) {
Logger.getLogger(RunMotor.class.getName()).log(Level.SEVERE, null, ex);
}
}
}
...
最後に
leJOS のオリジナルのサイトでは Eclipse でプラグインをインストールし ant を用いて開発する方法が紹介されていました。Eclipse ユーザの方はオリジナル・サイトをご参照いただければ幸いです。一応、私も Eclipse で試しましたが、上記オリジナルサイトの記載内容に従い設定を行う事で Eclipse で開発からデプロイまで行う事ができる所までは確認しました。
普段、私は NetBeans を使用しているため、今回 NetBeans で同様に開発ができないか?!と考え、上記環境設定を行いました。一旦、上記 1 〜 4 までの設定を行うと、以降の開発は 5 〜 8 までを繰り返し行うだけで NetBeans でも簡単に開発ができるようになります。また Eclipse と同様に、ビルドを行った時点で自動的に WiFi 経由でデプロイができるようになるためとても便利です。
どうぞ、Java で LEGO Mindstorms をお楽しみください。
PS.
Java SE 8 のローンチ・イベントで発表された Java SE Embedded で LEGO Mindstorms の説明資料も参考として紹介します。
また、Java Champion の Adam Bien もRun Java 7u40 Embedded on Lego Mindstormsのエントリで leJOS を使用した LEGO Mindstorms の制御のデモも公開していますので併せてご紹介します。
追記メモ2.
Java SE Embedded 8 を使う場合の手順。
1. Oracle Java SE Embedded version 8 の DownLoad
Oracle Java SE Embedded version 8のダウンロード
上記のページ内に下記の記述があります。
Java SE Embedded 8 enables developers to create customized JREs using the JRECreate tool. Starting with Java SE Embedded 8, individual JRE downloads for embedded platforms are no longer provided. To get started, download the bundle below and follow instructions to create a JRE that suits your application’s needs.
これは、Java SE Embedded 8 以降では、Java SE 7 のように個別の JRE を提供しないため、自分専用の JRE を、JRECreate ツールを使って作成する必要がある事が書かれています。
2. Create a Custom JRE with jrecreate
jrecreate コマンドを使用してカスタムの JRE を作成してください。
※ jrecreate コマンドの引数の詳細は下記をご参照ください。
jrecreate Options
上記、説明内容に従って、カスタムの JRE を作成してください。
| > tar xvfz ejdk-8-fcs-b132-linux-arm-sflt-03_mar_2014.tar.gz > cd ejdk1.8.0/ > ls bin lib linux_arm_sflt > cd bin > ./jrecreate.sh -vm all -d /tmp/ejre1.8.0 Options { ejdk-home: /Users/USER_NAME/Downloads/ejdk1.8.0 dest: /tmp/ejre1.8.0 target: linux_arm_sflt vm: all runtime: jre debug: false keep-debug-info: false no-compression: false dry-run: false verbose: false extension: [] } を使用してJREを作成しています ターゲットJREサイズは45,523 KBです(ディスクの使用量はこれより多いことがあります)。 |
SD カードにファイルをコピーして展開した後、SD ディスクをアンマウントしてください。後は、上記 (2)ブート可能なマイクロ SD カードから起動(EV3 で実施)と同様に、作成した SD から EV3 を起動して(2)以降の処理を行ってください。
上記で、Java SE Embedded 8 で制御できるようになります。
Java SE 8 Embedded のコードを実装するためには、Maven の pom.xml の下記の行 (コンパイラのソース、ターゲット) をそれぞれ 1.7 → 1.8 に修正して実装してください。
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
備考:本来であれば、LEGO Mindstorms は Java SE Embedded 8 の “Compact Profile 2” で動作するようなのですが、現在 Compact Profile 2 で JRE を作成した場合は現時点で動作しません。本件は、leJOS のチームと Oracle の Embedded チームが現在調査中です。
上記は現時点(2014年4月28日時点)でのワークアラウンドとしてご利用ください。
jBatch(JSR-352) on Java SE 環境
先日のデブサミの発表後、jBatch (JSR-352) についてご質問を頂き、また別件でも同じ質問を頂きましたので、その内容を共有致します。
jBatch を cron 等で実行したいのだが、jBatch は Java EE 環境でしか実行できないのか?とのご質問を頂きました。
答えは、jBatch の仕様上、Java SE 環境上でも動作するように実装されております。
ただし、Java EE 環境上で実装する方がとても簡単に実装・運用ができますので個人的にはJava EE 環境上での動作をお薦めします。仮に Java SE 環境上で jBatch (jBatch の RI)を実行したい場合は下記をご参照ください。
1. 準備
Java SE 環境上で jBatch を稼働させるためには、JavaDB(Derby) が必要です。
また、jBatch の RI を使って Java SE 環境上で動作させるためには、
jBatch RI の実行に必要なライブラリ一式を下記より入手します。
https://java.net/projects/jbatch/downloads/download/jsr352-SE-RI-1.0.zip
zip を展開すると下記のファイルが含まれています。下記全ファイルを lib 配下にコピーしてください。
- derby.jar
- javax.inject.jar
- jsr352-SE-RI-javadoc.jar
- javax.batch.api.jar
- jsr352-RI-spi.jar
- jsr352-SE-RI-runtime.jar
2. Batch コンテナを実行するための設定
次に Batch コンテナを稼働させるためのプロパティの設定を行います。
META-INF ディレクトリ配下に services ディレクトリを作成して
それぞれ下記のファイルを作成してください。
src/META-INF/services/batch-config.properties
JDBC_DRIVER=org.apache.derby.jdbc.EmbeddedDriver # JDBC_URL=jdbc:derby://localhost:1527/batchdb;create=true JDBC_URL=jdbc:derby://localhost:1527/batchdb
src/META-INF/services/batch-services.properties
J2SE_MODE=true
以上で基本的には Java SE 環境上で動作させるために必要な設定は完了です。
3. 動作確認
それでは、バッチであるファイルの内容を別のファイルに書き出すサンプルを作成します。(※ 以降は Java EE 環境での実装と同じです。)
下記に、本 jBatch プロジェクトのディレクトリ構成を下記に示します。

まず、メイン・メソッドから Batch の JOB: “my-batch-job” を起動します。
package com.yoshio3.main;
import java.util.Properties;
import javax.batch.operations.JobOperator;
import javax.batch.runtime.BatchRuntime;
/**
*
* @author Yoshio Terada
*/
public class StandAloneBatchMain {
public static void main(String... args) {
JobOperator job = BatchRuntime.getJobOperator();
long id = job.start("my-batch-job", new Properties());
}
}
この、”my-batch-job” の処理内容は、META-INF/batch-jobs ディレクトリ配下に、”my-batch-job.xml” として定義します。
“my-batch-job” の内容を下記に示します。プロパティを2つ input_file,output_file 定義し、それぞれ /tmp/input.txt, /tmp/output.txt を示します。また、JOB の step としてチャンク形式の step を1つ定義し、データの読み込み用(reader)、処理用(processor)、書き込み(writer)用の処理を、それぞれ、MyItemReader, MyItemProcessor, MyItemWriter に実装します。
<job id="my-batch-job"
xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<properties>
<property name="input_file" value="/tmp/input.txt"/>
<property name="output_file" value="/tmp/output.txt"/>
</properties>
<step id="first-step">
<chunk item-count="5">
<reader ref="com.yoshio3.chunks.MyItemReader"/>
<processor ref="com.yoshio3.chunks.MyItemProcessor"/>
<writer ref="com.yoshio3.chunks.MyItemWriter"/>
</chunk>
</step>
</job>
読み込み用の処理は、ItemReader を実装したクラスを作成します。ここでは、input_file で指定されたプロパティのファイル(/tmp/input.txt)ファイルを読み込み、1行読み込んでその値を返します。
package com.yoshio3.chunks;
import java.io.BufferedReader;
import java.io.Serializable;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Paths;
import javax.batch.api.chunk.ItemReader;
import javax.batch.runtime.context.JobContext;
import javax.inject.Inject;
public class MyItemReader implements ItemReader {
@Inject
JobContext jobCtx;
BufferedReader bufReader;
@Override
public void open(Serializable checkpoint) throws Exception {
String fileName = jobCtx.getProperties()
.getProperty("input_file");
bufReader = Files.newBufferedReader(Paths.get(fileName),Charset.forName("UTF-8"));
}
@Override
public void close() throws Exception {
bufReader.close();
}
@Override
public Object readItem() throws Exception {
String data = bufReader.readLine();
System.out.println("Reader readItem : " + data);
return data;
}
@Override
public Serializable checkpointInfo() throws Exception {
return null;
}
}
次に、読み込んだデータの加工処理部分は、ItemProsessor を実装したクラスに記述します。ここでは、読み込んだデータ(文字列)に対して、文字列を付加して返しています。
package com.yoshio3.chunks;
import javax.batch.api.chunk.ItemProcessor;
/**
*
* @author Yoshio Terada
*/
public class MyItemProcessor implements ItemProcessor {
@Override
public Object processItem(Object item) throws Exception {
String line = (String)item ;
StringBuilder sBuilder = new StringBuilder();
sBuilder.append("Processor processItem : ");
sBuilder.append(line);
String returnValue = sBuilder.toString();
System.out.println(returnValue);
return returnValue;
}
}
最後に書き出し部分を ItemWriter を実装したクラスに記述します。ここでは、oputput_file のプロパティを取得して書き出すファイル名を取得しています。次にファイルに対して取得したデータを書き出しています。
package com.yoshio3.chunks;
import java.io.BufferedWriter;
import java.io.Serializable;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
import javax.batch.api.chunk.ItemWriter;
import javax.batch.runtime.context.JobContext;
import javax.inject.Inject;
/**
*
* @author Yoshio Terada
*/
public class MyItemWriter implements ItemWriter {
@Inject
JobContext jobCtx;
String fileName;
BufferedWriter bufWriter;
@Override
public void open(Serializable checkpoint) throws Exception {
fileName = jobCtx.getProperties()
.getProperty("output_file");
bufWriter = Files.newBufferedWriter(Paths.get(fileName), Charset.forName("UTF-8"));
}
@Override
public void close() throws Exception {
bufWriter.close();
}
@Override
public void writeItems(List<Object> items) throws Exception {
for (Object obj : items) {
String data = (String) obj;
System.out.println("Writer writeItems : " + data);
bufWriter.write(data);
bufWriter.newLine();
}
}
@Override
public Serializable checkpointInfo() throws Exception {
return null;
}
}
上記を実装した後、コンパイルをしてください。
# java -classpath
lib/jsr352-ri-1.0/javax.inject.jar:
lib/jsr352-ri-1.0/derby.jar:
lib/jsr352-ri-1.0/jsr352-RI-spi.jar:
lib/jsr352-ri-1.0/javax.batch.api.jar:
lib/jsr352-ri-1.0/jsr352-SE-RI-javadoc.jar:
lib/jsr352-ri-1.0/jsr352-SE-RI-runtime.jar:
build/classes com.yoshio3.main.StandAloneBatchMain
実行すると下記のようなログを確認できます。chunk 形式ではデフォルトで 10 件まとめて読み込み&処理を実施し、
まとめて 10 件書き込むという動作を下記からも確認できるかと思います。
2 18, 2014 12:10:50 午後 com.ibm.jbatch.container.services.impl.JDBCPersistenceManagerImpl createSchema 情報: JBATCH schema does not exists. Trying to create it. 2 18, 2014 12:10:50 午後 com.ibm.jbatch.container.services.impl.JDBCPersistenceManagerImpl createIfNotExists 情報: CHECKPOINTDATA table does not exists. Trying to create it. 2 18, 2014 12:10:50 午後 com.ibm.jbatch.container.services.impl.JDBCPersistenceManagerImpl createIfNotExists 情報: JOBINSTANCEDATA table does not exists. Trying to create it. 2 18, 2014 12:10:50 午後 com.ibm.jbatch.container.services.impl.JDBCPersistenceManagerImpl createIfNotExists 情報: EXECUTIONINSTANCEDATA table does not exists. Trying to create it. 2 18, 2014 12:10:50 午後 com.ibm.jbatch.container.services.impl.JDBCPersistenceManagerImpl createIfNotExists 情報: STEPEXECUTIONINSTANCEDATA table does not exists. Trying to create it. 2 18, 2014 12:10:50 午後 com.ibm.jbatch.container.services.impl.JDBCPersistenceManagerImpl createIfNotExists 情報: JOBSTATUS table does not exists. Trying to create it. 2 18, 2014 12:10:50 午後 com.ibm.jbatch.container.services.impl.JDBCPersistenceManagerImpl createIfNotExists 情報: STEPSTATUS table does not exists. Trying to create it. Reader readItem : hogehoge1 Processor processItem : hogehoge1 Reader readItem : hogehoge2 Processor processItem : hogehoge2 Reader readItem : hogehoge3 Processor processItem : hogehoge3 Reader readItem : hogehoge4 Processor processItem : hogehoge4 Reader readItem : hogehoge5 Processor processItem : hogehoge5 Reader readItem : hogehoge6 Processor processItem : hogehoge6 Reader readItem : hogehoge7 Processor processItem : hogehoge7 Reader readItem : hogehoge8 Processor processItem : hogehoge8 Reader readItem : hogehoge9 Processor processItem : hogehoge9 Reader readItem : hogehoge10 Processor processItem : hogehoge10 Writer writeItems : Processor processItem : hogehoge1 Writer writeItems : Processor processItem : hogehoge2 Writer writeItems : Processor processItem : hogehoge3 Writer writeItems : Processor processItem : hogehoge4 Writer writeItems : Processor processItem : hogehoge5 Writer writeItems : Processor processItem : hogehoge6 Writer writeItems : Processor processItem : hogehoge7 Writer writeItems : Processor processItem : hogehoge8 Writer writeItems : Processor processItem : hogehoge9 Writer writeItems : Processor processItem : hogehoge10 Reader readItem : hogehoge11 Processor processItem : hogehoge11 Reader readItem : hogehoge12 Processor processItem : hogehoge12 Reader readItem : hogehoge13 Processor processItem : hogehoge13 Reader readItem : hogehoge14 Processor processItem : hogehoge14 Reader readItem : hogehoge15 Processor processItem : hogehoge15 Reader readItem : hogehoge16 Processor processItem : hogehoge16 Reader readItem : hogehoge17 Processor processItem : hogehoge17 Reader readItem : hogehoge18 Processor processItem : hogehoge18 Reader readItem : hogehoge19 Processor processItem : hogehoge19 Reader readItem : hogehoge20 Processor processItem : hogehoge20 Writer writeItems : Processor processItem : hogehoge11 Writer writeItems : Processor processItem : hogehoge12 Writer writeItems : Processor processItem : hogehoge13 Writer writeItems : Processor processItem : hogehoge14 Writer writeItems : Processor processItem : hogehoge15 Writer writeItems : Processor processItem : hogehoge16 Writer writeItems : Processor processItem : hogehoge17 Writer writeItems : Processor processItem : hogehoge18 Writer writeItems : Processor processItem : hogehoge19 Writer writeItems : Processor processItem : hogehoge20 Reader readItem : null
書き込む間隔を変更したい場合は、Job XML の設定を変更し<chunk item-count=”5″>を設定します。
<job id="my-batch-job"
xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<properties>
<property name="input_file" value="/tmp/input.txt"/>
<property name="output_file" value="/tmp/output.txt"/>
</properties>
<step id="first-step">
<chunk item-count="5">
<reader ref="com.yoshio3.chunks.MyItemReader"/>
<processor ref="com.yoshio3.chunks.MyItemProcessor"/>
<writer ref="com.yoshio3.chunks.MyItemWriter"/>
</chunk>
</step>
</job>
<chunk item-count=”5″>を設定した後、実行すると下記のような結果が得られます。
run: Reader readItem : hogehoge1 Processor processItem : hogehoge1 Reader readItem : hogehoge2 Processor processItem : hogehoge2 Reader readItem : hogehoge3 Processor processItem : hogehoge3 Reader readItem : hogehoge4 Processor processItem : hogehoge4 Reader readItem : hogehoge5 Processor processItem : hogehoge5 Writer writeItems : Processor processItem : hogehoge1 Writer writeItems : Processor processItem : hogehoge2 Writer writeItems : Processor processItem : hogehoge3 Writer writeItems : Processor processItem : hogehoge4 Writer writeItems : Processor processItem : hogehoge5 Reader readItem : hogehoge6 Processor processItem : hogehoge6 Reader readItem : hogehoge7 Processor processItem : hogehoge7 Reader readItem : hogehoge8 Processor processItem : hogehoge8 Reader readItem : hogehoge9 Processor processItem : hogehoge9 Reader readItem : hogehoge10 Processor processItem : hogehoge10 Writer writeItems : Processor processItem : hogehoge6 Writer writeItems : Processor processItem : hogehoge7 Writer writeItems : Processor processItem : hogehoge8 Writer writeItems : Processor processItem : hogehoge9 Writer writeItems : Processor processItem : hogehoge10 Reader readItem : hogehoge11 Processor processItem : hogehoge11 Reader readItem : hogehoge12 Processor processItem : hogehoge12 Reader readItem : hogehoge13 Processor processItem : hogehoge13 Reader readItem : hogehoge14 Processor processItem : hogehoge14 Reader readItem : hogehoge15 Processor processItem : hogehoge15 Writer writeItems : Processor processItem : hogehoge11 Writer writeItems : Processor processItem : hogehoge12 Writer writeItems : Processor processItem : hogehoge13 Writer writeItems : Processor processItem : hogehoge14 Writer writeItems : Processor processItem : hogehoge15 Reader readItem : hogehoge16 Processor processItem : hogehoge16 Reader readItem : hogehoge17 Processor processItem : hogehoge17 Reader readItem : hogehoge18 Processor processItem : hogehoge18 Reader readItem : hogehoge19 Processor processItem : hogehoge19 Reader readItem : hogehoge20 Processor processItem : hogehoge20 Writer writeItems : Processor processItem : hogehoge16 Writer writeItems : Processor processItem : hogehoge17 Writer writeItems : Processor processItem : hogehoge18 Writer writeItems : Processor processItem : hogehoge19 Writer writeItems : Processor processItem : hogehoge20 Reader readItem : null
以上のように、Java SE の環境でも jBatch (JSR-352) を実行する事ができます。今回は参考のため jBatch の RI を使用しましたが、各 Java EE 7 準拠のアプリケーション・サーバで必要なライブラリはそれぞれ異なるかと想定します。必要なライブラリは各アプリケーション・サーバでお調べください。
Java EE 7 トレーニング・コースについて
Oracle University では、現在 Java EE 7 のトレーニング・コース(Java EE 7: New Features Coming Soon (¥145,530) )を全世界への提供に向けて準備しています。
これは、Java EE 7 に含まれる新機能を2日間で紹介し、加えてラボで実際に手を動かしながら演習を行うこともできるトレーニング・コースになっています。これによりいち早く Java EE 7 の全体像とプログラミング方法を習得できます(このトレーニング・コースに関してはレビューの要望が私の元にも入ってきたため、一部私もレビューをし改善を加えた部分もあります)。
本トレーニング・コースでは Batch, JSON, WebSocket, JAX-RS, EL 3.0, JMS 2.0 , EJB, JPA, CDI, Bean Validation 等 Java EE 7 に含まれるの技術をとりあげ、既存のアプリケーションを Java EE 7 に対応させるために必要な情報も提供してくれます。
本トレーニング・コースについて日本の担当者と話をした所、本コースは世界で正式公開された後も、現時点では英語でのみ提供予定のようです。ただし、日本の Oracle University に対して、日本語での開催リクエストを行い、かつご希望者が多い場合、日本人講師による日本語でのサービス提供も可能との事でした。
Java EE 7 のトレーニング・コースを日本語で受講されたい方は、今から本トレーニング・コースに対する日本語開催リクエストを出されてみては如何でしょうか。

トレーニングの紹介ページにアクセスした後、「コース開催日のリクエスト」を押下するとリクエストを行う事ができます。途中の質問で「集合研修(Clasroom Training)」にチェックしてください。

どうぞ宜しくお願いします。
Virtual Developer Day-Java 開催 (6/19 or 6/25)

Oracle Technology Network (通称:OTN) 主催で Virtual Developer Day : Java が開催されます。下記のスケジュールに詳細を記述していますが、Java SE/FX/Embedded/EE の各テクノロジーに関して、無償で、オンラインでご覧頂く事ができます。Java SE 8 に含まれる 52 の新機能、Lambda 式、JavaFX、Java EE 7、Raspberry Pi など各テクノロジーの最新情報をご確認いただけます。またライブ・チャットもご用意しておりますので、エキスパートに対して直接質問を投げかける事もできます。本イベントにご興味のある方はご登録の上受講してください。
(※ 日本の開発者の皆様は恐らく 6 月 25 日開催のヨーロッパ向けの方が受講しやすい時間帯かと思います。)
- アメリカ :6 月 19 日(日本時間夜中の1時〜5時)
- ヨーロッパ:6 月 25 日(日本時間夕方5時〜9時)
詳しくは、コチラをご参照ください。

JJUG CCC 2013 Spring の発表資料について
本日、JJUG CCC 2013 Spring が開催されました。Oracle からはUS Oracle Corporation からJim Weaver (Twitter : @JavaFXpert) が基調講演で「What’s New for JavaFX in JDK 8」を発表し、午後一のセッションで、「Java EE 6 から Java EE 7 に向かって」というセッションを担当しそれぞれ発表しました。2人の発表資料を公開しましたのでご報告します。
(※ 私のプレゼン資料ですが、SlideShare にアップロードした際、SlideShare 側の問題で、フォントが無いせいか、私が使用しているオリジナル・フォントからは変わって表示されています。その点ご了承頂ければ幸いです。)
基調講演-2 What’s New for JavaFX in JDK 8
H-1 Java EE 6 から Java EE 7 に向かって
今日の私のプレゼン中で行った EL(Expression Language) 3.0のデモのソース・コードも下記に公開します。デモ用に簡単に作ったものであるため、本来 JPA で DB 接続すべき所を簡単にダミーデータ(Person#createDummyData())を作成しています。
本コードは JSF 2.0 と CDI をご存知の方であれば容易にご理解いただけるかと思いますが、「全データ抽出」のボタンを押下すると、CDI の getAllData() が呼び出され、indexManagedBean.data(ArrayList) に全データがコピーされ、その一覧が dataTable に表示されます。
次に、「年齢フィルタ」のテキストフィールド(デフォルト:0)に対して年齢を入力すると、入力された年齢以上のデータを表示しています。内部的には Ajax を使って、入力された年齢情報(indexManagedBean.ageFileter)をサーバに送信し、Ajax のリスナーとして定義しているindexManagedBean.updateData()を実行していいます。ただ、indexManagedBean.updateData()は処理は何もしていません、ここでは execute=”ageFilter” をサーバに送信し、その結果を render=”tabledata” 、つまり dataTable の内容を更新するためだけにupdateData()を呼び出しています。
<h:dataTable id="tabledata" value="#{afilter = indexManagedBean.ageFileter;indexManagedBean.data.stream().filter(p-> p.age >= afilter).toList()}" var="person" border="1">
この例では、一度 DBに対してクエリを実行し、その結果をコレクションにコピーした後、さらにそのコピーしたデータに対して絞り込みを行っています。DB に対して再度クエリをなげるのではなく、EL 3.0 の Lambda 式を使って、一旦取得したデータを元に再フィルタリングを 行っています。
セッション中でも話をしましたが EL 3.0 で Lambda 式(及び LINQ 式)が使えるようになった事でビューにロジックを埋め込む事が可能になりますが、あまりやりすぎると可読性の低下にもつながりますので使う範囲はよくご検討頂いた方がよいのではないかと思います。(※ .Net の LINQ 式は DB に対しても操作可能ですが、EL 3.0 における LINQ 式はコレクションに対してのみ有効です。)
今回の例では、一旦取得したデータのフィルタンリグ等でご使用頂く事で、DB に対する負荷、インメモリ・グリッドにあるキャッシュから取得するよりもパフォーマンスがよくなる事を想定し記載しています。なぜならばヒープメモリ内にあるデータを直接操作する方がパフォーマンス的に優れるためです。(※ コレクションに対して有効な操作である事をご認識頂き用途は十分にご検討ください。)
<?xml version='1.0' encoding='UTF-8' ?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:f="http://java.sun.com/jsf/core"
xmlns:h="http://java.sun.com/jsf/html"
>
<h:head>
<title>Facelet Title</title>
</h:head>
<h:body>
<h:form>
<h:commandButton value="全データ抽出" action="#{indexManagedBean.getAllData()}"/><br/>
<h:outputLabel value="年齢フィルタ"/>:
<h:inputText id="ageFilter" value="#{indexManagedBean.ageFileter}" autocomplete="off">
<f:ajax event="keyup" execute="ageFilter" render="tabledata" listener="#{indexManagedBean.updateData()}"/>
</h:inputText>
<h:dataTable id="tabledata" value="#{afilter = indexManagedBean.ageFileter;indexManagedBean.data.stream().filter(p-> p.age >= afilter).toList()}" var="person" border="1">
<h:column>
<f:facet name="header">
<h:outputText value="名前"/>
</f:facet>
<h:outputText value="#{person.name}"/>
</h:column>
<h:column>
<f:facet name="header">
<h:outputText value="年齢"/>
</f:facet>
<h:outputText value="#{person.age}"/>
</h:column>
<h:column>
<f:facet name="header">
<h:outputText value="性別"/>
</f:facet>
<h:outputText value="#{person.sex}"/>
</h:column>
</h:dataTable>
</h:form>
</h:body>
</html>
package jp.co.oracle.ee7samples.cdi;
import java.util.ArrayList;
import javax.faces.view.ViewScoped;
import javax.inject.Named;
import jp.co.oracle.ee7samples.model.Person;
@Named
@ViewScoped
public class IndexManagedBean {
private ArrayList data;
private Integer ageFileter;
public ArrayList getData() {
return data;
}
public void setData(ArrayList data) {
this.data = data;
}
public Integer getAgeFileter() {
if (ageFileter == null) {
return new Integer(0);
}
return ageFileter;
}
public void setAgeFileter(Integer ageFileter) {
this.ageFileter = ageFileter;
}
public String getAllData() {
setData(Person.createDummyData());
return "";
}
public String updateData() {
return "";
}
}
デモの中でもお伝えしましたが、本来 JPA で DB に接続して Person Entity に対して全レコードを抽出するコードを書く方が現実的なのですが、EL 3.0 は本来 Collection を対象とする事をわかりやすくするため、JPA を使わずに自分でダミーのデータをcreateDummyData()で作成しています。
package jp.co.oracle.ee7samples.model;
import java.util.ArrayList;
public class Person {
private String name;
private Integer age;
private String sex;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public static ArrayList createDummyData() {
ArrayList<Person> data = new ArrayList<>();
Person person;
for (int i = 0; i < 100; i++) {
person = new Person();
person.setAge(Integer.valueOf(i));
if (i % 2 == 1) {
person.setName("山田 太郎" + i);
person.setSex("男性");
} else {
person.setName("山田 花子" + i);
person.setSex("女性");
}
data.add(person);
}
return data;
}
}
デブサミの発表資料公開と Java イベントのご案内
![]()
2013年2月14日(木)・15日(金)目黒雅叙園で開催された Developers Summit 2013 (通称 デブサミ2013)に参加しました。今回のデブサミのテーマは Action という事で、Java で今現在とるべき Action 、将来に備えた Action を下記に分類し紹介致しました。
● 今とるべき Action
1. Java SE 7 のご適用
2. JavaFX の導入
3. Java EE 6 のご適用
● 将来に備えて準備 Action
4. Java EE 7 の情報収集&事前検証
5. Java SE 8 の情報収集&事前検証
● 今後の情報収集、貢献などの Action
6. Participation (参加)
7. Java イベントのご案内 (2013/5/14)
発表の中で、
オラクル主催の Java イベントの日程も公開致しました。追って詳細はご案内致しますが、日程は、2013 年 5 月 14 日(火)に正式決定致しました。
昨年の JavaOne Tokyo 後から、多くの Java 技術者の皆様から次回の JavaOne Tokyo の開催希望を頂いておりました(Togetter : またJavaOne Tokyoやってほしいなぁ)。このように開発者の皆様から頂いたお声に応えるために、かねてより社内で Java セミナー開催の企画を行なっておりましたが、ようやく日程を正式に公開できる運びとなりました。今回のイベントは、JavaOne という名前のイベントではございませんが、丸1日 Java の技術だけを扱うイベントになります。また昨年の JavaOne Tokyo 同様、海外からエンジニアを呼ぶ事も決まっております。
Java の開発者の皆様におかれましては、是非今から 5 月 14 日(火)のスケジュールを確保頂き、是非、本イベントまで足をお運びいただければ誠に幸いです。
また、上記イベントの直前である、5 月 11 日(土)には、日本 Java ユーザ・グループでも JJUG CCC Spring 2013 の開催を予定しております。そして只今、JJUG CCC Call for Papers の募集も行なっていますので、JJUG のイベントで登壇してみたいという方がいらっしゃいましたら、是非 Call for Papers へご応募ください。
ゴールデン・ウィーク後1週間は、日本で Java ウィークになりますので、皆様どうぞ楽しみにしていてください。
両イベントで皆様とお会いできる事を心より楽しみに致しております。
WebLogic Server 12c Forum 2013 開催

「WebLogic Server 12c Forum 2013
~ Java EEの現在と未来、WebLogicが拓く新たな可能性 ~ 」
日時 :2013年2月1日(金)13:30~17:30 (受付開始 13:00~)
場所: オラクル青山センター
〒107-0061 東京都港区北青山2-5-8
お申し込み:コチラから
2013/02/01 にオラクル青山センターで WebLogic/Java EE 関連のイベントを開催します。本セミナーでは US 本社より Fusion Middleware の Product Management である、マイク・リーマンを招き、世界のJava EE 6活用状況や、昨年開催した Oracle OpenWorld における WebLogic Server の最新情報、さらには今後のWebLogic の姿に至るまで、様々なトピックをご紹介致します。
| アジェンダ
13:30~13:35 開催のご挨拶 |
個人的には、中でも Oracle RAC の性能を最大限に引き出す Active GridLink for RAC の性能検証に興味があります。これは Oracle と NEC さんとで実際に検証を行なった内容の詳細を発表する予定ですが、とても興味深い内容です。
皆様のご参加を心よりお待ち申し上げます。
JavaOne 2011 サンフランシスコ

コミュニティからの多大な建設的なご意見とご支援を頂いた後、我々は 2011年10月2日から6日までの間、サンフランシスコで JavaOne 2011 の開催を決定した事をここにお知らせします。JavaOne イベントに対する投資の拡大と、イベントに対する多くの大幅な改善により、Oracle は JavaOne を再び成功させるために、今年もそして今後も取り組んでまいります。
過去 15 年間、JavaOne は Java コミュニティと共に協力して教育イベントを導いてきました。今年は 待望の JDK 7 や JavaFX 2.0 がリリースされる Java にとってエキサイティングな年になり、イベントでは今までと同様、最新の技術コンテンツを提供する他、今後 Java が提供する新機能等の情報を提供します。
また前回の JavaOne カンファレンスと同様、Oracle は今年のイベントで提供するコンテンツを作成するため、 Java コミュニティのリーダを通じてアイディアを募集しています。2010 年のコンテンツ制作メンバーはこちらからご確認いただけます。 JavaOne Program Review Committee page
Call for Papers
我々は、Call for Papers の募集開始を 4/27 を予定し 5/23 に終了する事を予定しています。そこで募集開始のアナウンスを注意してお待ちください。今年は下記の技術的トラックが用意されており、これらの技術トピックの中から検討し応募頂く事が可能です。
1. コア Java プラットフォーム
2. 新しいプログラミング言語、ツール、技術
3. エンタープライズ・サービス・アーキテクチャやクラウド
4. Java EE Web プロファイルや Enterprise Platform の技術
5. Java ME, モバイル, 組み込み、デバイス
6. Java SE, クライアント技術、リッチクライアント技術
7. Java フロンティア
Call For Papers に対して何らかの疑問がある場合は、speaker-services_ww@oracle.com までどうぞご連絡ください。
JavaOne カンファレンスの改善
- Oracle OpenWorld と同一週にイベントは開催されますが、JavaOne は、独自の完全専用会議スペースを用意し OpenWorld とは別イベントとして、また単独カンファレンスとして開催します。
- 技術セッションや、BoF、ハンズオンラボを含むコンテンツを増加します。
- カンファレンス開催期間中、開発者が対話やコラボレーションできるような時間と空間を提供します。
- イベントの計画や進行に関してコミュニティの代表者に直接関与して頂きます。
登録
カンファレンスの経験を最大限に活用する最善の方法は、イベントに対する早期の登録とホテルのベストレートを確保する事です。早期登録により、より良い宿泊オプションを得る事ができるでしょう。 ご登録はこちらから
JavaOne に関する情報提供の継続
JavaOne カンファレンスに関するニュースを継続して受け取りたい場合、 JavaOne Conference blog をブックマークして頂くか、もしくは web site へご訪問ください。また下記の SNS を利用する事も可能です。
• Twitter: @javaoneconf
• Facebook: http://www.facebook.com/javaone
• LinkedIn: http://www.linkedin.com/groups?gid=1749197
この記事は下記の記事の翻訳です。
JavaOne 2011
EJB 3.1 の新機能概要
EJB 3.1 の新機能をプレゼン形式でまとめてみました。
かんたんに概要を紹介します。
EJB 3.0 から EJB 3.1 になり、かんたん開発に向けて多くの改善が施されています。まず、パッケージの簡略化が挙げられます。今までアプリケーションの種類に応じて .ear, .war 等のアーカイブにまとめる必要がありましたが、EJB コンポーネントも .war に含めることができるようになったため開発時の手間が大幅に削減されます。また、EJB 3.1 Lite が提供されフル Java EE の機能の一部の機能だけを利用できるようになったため、フル Java EE の機能が必要ないお客様にとっては不要なメモリリソースを消費せずに運用できる等のメリットがあります。
次のポイントはローカルビジネスインタフェースの実装が必要なくなった点です。これは開発者の生産性が向上するだけではなく、修正の手間も大幅に削減してくれます。例えば、過去に実装したクラスにおいて、特定のメソッドに対する引数や返り値の変更が必要になった場合を想定してください。今まではインタフェースのメソッド定義と実装クラスのメソッド定義を両方変更しなければなりませんでしたが、インタフェースの定義が必要がなくなったため、実装クラスのメソッド定義を変更するだけでよくなります。
次に、移植可能な Global JNDI 名では、今までベンダー独自に実装していた Global の JNDI 名が仕様の中で標準化されましたので、今後アプリケーションを他のアプリケーションサーバへ移行したいような場合、Global JNDI 名を変更する必要がなくなり移植性が高まります。
また、Java SE に組み込み可能な EJB コンテナ は開発時におけるテストの手間を大幅に削減してくれるようになります。今までは EJB のアプリケーションをテストする際、アプリケーションサーバにデプロイして Global 経由でアクセスする等の必要がありました。これは別の Java VM のプロセスとして稼働するためデバッグ等も困難でしたが、EJB 3.1 では Java SE のプロセス内に EJB コンテナをロードして実行する事ができるようになるため、同一 Java プロセス内で処理ができる他、EJB の単体テスト等がしやすくなります。
その他の追加機能として、Singleton Session Beans が追加された事が挙げられます。これはアプリケーション間で同一の情報を扱いたい場合に有効です。今までは独自に Singleton のクラスを作成して運用しなければなりませんでしたが、クラスタ環境のように複数台で実現するためには苦労していたかと思います。なぜなら異なる JVM プロセスの間で Sigleton のインスタンスを共有させる事は面倒だったからです。しかしEJB 3.1で提供する Singleton Session Bean はコンテナを跨ぐ環境においても唯一のインスタンスが保障されるため、こういった実装の手間が必要なく、アノテーションの追加だけで利用できるようになります。その他、タイマーサービスや非同期処理もそれぞれアノテーションを利用して簡単に実装できるようになっています。
最後に、
EJB といえば実装が難しい、設定も面倒という時代は今や過去の事で、今では実装がとてもかんたんになっています。また便利な機能をデフォルトで数多く持っている便利なフレームワークですので、今一度EJB を見直し利用をご検討ください。



























Java SE 5 Update 19 リリース
Java エバンジェリストの戸島さんから教えて頂いたのですが、
Java SE 5 Update 19 がリリースされたようです。
このバージョンから IE8, Windows Server 2008 がサポートされるように
なったとようです。configuration の page には vista もリストされているので
vista も対応されたようです。
http://java.sun.com/j2se/1.5.0/ReleaseNotes.html#150_19
http://java.sun.com/j2se/1.5.0/system-configurations.html
IE8, Windows Server 2008, Vista ユーザの皆様
お待たせいたしました。


