Java on Azure Day 2023 開催のお知らせ
皆様この度、日本マイクロソフト株式会社主催の Java 技術カンファレンス「Java on Azure Day 2023」の開催が決まりました。
- 日時:2023 年 4月 26 日 10時〜18時
- 場所:日本マイクロソフト株式会社 品川本社オフィス 31F セミナールーム
- 登録サイト:https://msevents.microsoft.com/event?id=3692399073
COVID-19 以降、様々なテクノロジー・カンファレンスがオンライン化され、Java on Azure Day も過去2回はオンラインで開催しました。しかし今回は、完全なオフラインの対面イベントとして開催します。(現時点でオンライン配信の予定はございません)
2年前は当たり前だった対面形式のイベントを思い出し、対面だからこそ得られる体験、そして直接お会いして交流する喜びをもう一度取り戻したいと考えています。
- 対面形式で行う生セッション (オンラインとは違う生セッションの緊張感)
- エキスパートと直接会話、相談、問い合わせ、フィードバックができる
- 新しい人と人との出会いや繋がり、新しいネットワーク作り
現時点では、まだセッションのリストは公開していませんが、徐々にセッションの内容も決まってきています。もうすぐでセッション・リストを公開する予定ですが、豪華なスピーカーの皆様に、各技術の最新動向や詳細についてご登壇いただく予定でございます。純粋な Java の最新技術から、Java on Azure に関する最新動向、さらにはマイクロソフトのパートナー企業の動向まで、たった1日で様々な技術を学べます。
全セッション終了後に、参加者の皆様にご参加いただく事が可能なネットワーク・パーティも用意しています。この2年間ネットワーク経由でしか会えなかった方々と直接お会いできるチャンスの他、初めて対面イベントに参加される方も新しい人脈を作ることのできる貴重な機会です。
ぜひ、この久しぶりに開催するオフラインの対面イベントにお越しください。
どうぞ宜しくお願いします。
寺田
WebLogic on Azure VM が正式リリース
Azure Linux 仮想マシンで OracleWebLogic Server(WLS)が正式に利用可能になったことをお知らせします。
このリリースは、Microsoft と Oracle の幅広いパートナーシップの一環として、WebLogic チームと共同で開発しました。
このパートナーシップには、Oracle/Microsoft および Azure で実行されているさまざまな Oracle ソフトウェアのサポートも含まれます。
Azure AD で OpenID Connect を使用したセキュアな Open Liberty アプリケーションの構築
* Application Development
* Cloud
* Tutorials and Demos
* Community/partners
Web アプリケーションで、ユーザーアカウントを独自に作成したり、認証・認可を個別に実装・管理する時代は終わりました。
その代わりに、現在のアプリケーションは、外部プロバイダーを利用して、上記の機能(Identity and Access Management略してIAM)を実装します。 完全な Javaアプリケーションの実行基盤として存在する、Open Liberty は、外部プロバイダーの IAM を利用するための機能を備えています。Open Liberty はソーシャルメディア・ログイン、SAML Web シングルサインオン、OpenID Connect クライアントなど IAM の主要な機能をサポートしています。
Bruce Tiffany のブログ・エントリ 「Securing Open Liberty apps and microservices with MicroProfile JWT and Social Media login」では、Open Liberty ソーシャルメディア・ログインの機能を使用して、既存のソーシャルメディアの認証情報を使用してユーザー認証する方法を紹介しています。
このブログ・エントリでは上記とは別の方法をご紹介します。ここで Microsoft の Azure Active Directory で Java アプリケーションを保護するために、Liberty ソーシャルログイン機能を OpenID Connectクライアントとして実装する方法を見てみましょう。
このブログで紹介するサンプルコードは、全て コチラの GitHub リポジトリで公開しています。ブログをご覧頂く前後で、コードをチェックし、ユーザーガイドに従い Java EE サンプル・アプリケーションを実行してください。
Azure Active Directory のセットアップ
Azure Active Directory(Azure AD)は、認証プロトコルとして OAuth 2.0 上に OpenID Connect(OIDC)を実装しているため、Azure AD を利用したアプリケーションのセキュアなユーザー認証ができるようになっています。
サンプルコードをご覧いただく前に、Azure AD テナントをセットアップし、リダイレクト URL の設定とクライアントシークレットでアプリケーションを登録してください。
Azure AD のテナント・セットアップ時に取得する、テナントID、アプリケーション(クライアント)ID、およびクライアントシークレットは、Open Liberty が Azure AD と接続し OAuth 2.0 承認フローを行うために使用しますので情報を控えておいてください。
Azure AD の設定方法は、下記の記事をご参照ください。
* クイック スタート:テナントを設定する
* クイック スタート:Microsoft ID プラットフォームにアプリケーションを登録する
* 新しいアプリケーション シークレットを作成する
OpenID Connect クライアントとしてソーシャルログインを構成
下記のサンプルコードは、Open Liberty サーバーで実行されているアプリケーションが、どのようにして、Azure AD を使用した OpenID Connectプロバイダーに対して、socialLogin-1.0 の機能を持つ OpenID Connect クライアントからユーザー認証を行うのか、その方法を示しています。
関連するサーバー構成:server.xml

oidcLogin 要素は、Open Liberty が持つ多数の設定可能要素の一つです。
サンプル・コードで示すように、Azure AD は検出用のエンドポイントをサポートしているため、Azure AD を利用する場合、多くの設定は不要で、サンプル・コードで示すように、いくつかのオプションのみを使用します。
検出用のエンドポイントを利用すると、ほとんどの OpenID Connect の設定情報をクライアントが自動的に取得できるため、設定が大幅に簡素化できます。
さらに、特定の Azure AD インスタンスは、検出用エンドポイント URL に対して既知のパターンを適用するため、テナントID を使用して、URL をパラメーター化することもできます。
また、クライアントIDとシークレットが必要で、署名アルゴリズムとして RS256 を使用します。
userNameAttribute 属性は、Azure AD のトークンと Liberty の一意のサブジェクト ID にマップするために使用します。
使用可能な Azure AD トークンは、この一覧に示すようにいくつかあります。
v1.0 と v2.0 で必要なトークンは異なるため、注意が必要です(v2.0は一部のv1.0トークンをサポートしていません)。
preferred_username もしくは oid は共に安全に使用できますが、通常 preferred_username の使用をお勧めします。
Azure ADを使用すると、アプリケーションは、Microsoft の認証局 (Root CA) によって署名された証明書を使用できます。
この証明書を、JVM のデフォルトの cacerts に追加します。 JVM のデフォルトの cacerts を信頼することで、OIDC クライアントと Azure AD 間で SSL ハンドシェイクが成功することが保証されます(つまり、defaultSSLConfig trustDefaultCerts値を true に設定する)。
この場合、Azure AD を介して認証されたすべてのユーザーにユーザーロールを割り当てます。必要に応じて、Liberty でより複雑なロールマッピングも可能です。
OpenID Connect を使用したユーザー認証
サンプル・アプリケーションは JSF アプリとして公開します。ここでは “users” のロールを持つユーザーのみがアクセスできる Java EE セキュリティ規約を定義しています。
web.xmlの関連構成:

GitHub の web.xml へのリンクはコチラ
ワークフロー

図1:Azure AD で OpenID Connect を利用したトークン取得フロー
これは Java EE の標準セキュリティです。
認証されていないユーザーが JSF のアプリケーションに対してアクセスしようとすると、Azure AD の資格情報を取得するために Microsoft のサイトにリダイレクトされます。
成功すると、ブラウザは認証コードを含んでクライアントにリダイレクトします。
次に、クライアントは、再度 Microsoft のサイトに接続し、認証コード、クライアントID、シークレットを使用して IDトークンとアクセストークンを取得します。最後に、クライアントで認証済みユーザーを作成し、JSF アプリに対してアクセスします。
認証されたユーザー情報を取得するには、@ Injectアノテーションを使用してjavax.security.enterprise.SecurityContextへの参照を取得し、getCallerPrincipal() メソッドを呼び出します。

GitHub の Cafe.java へのリンクはコチラ
JWT RBACを使用したセキュアな内部 RESTful 呼び出し
JAX-RS で実装した RESTful Web サービスである Cafe Bean は CafeResource に依存し、コーヒーの作成、読み取り、更新、削除を行います。
CafeResourceは、MicroProfile JWT を使用して RBAC(ロールベースのアクセス・コントロール)を実装し、トークンのグループ要求を検証します。

GitHub の CafeResource.java へのリンクはコチラ
admin.group.id は、ConfigProperty アノテーションで定義する事で、MicroProfile Config を使用し、アプリケーションの起動時に値を注入します。
MicroProfile JWT では JWT(JSON Web トークン)を @Inject で注入きます。
CafeResource REST エンドポイントは、OpenID Connect の承認ワークフローに従い、Azure AD によって発行された ID トークンから、preferred_username および groups クレームを含む JWT を受け取ります。
ID トークンは、com.ibm.websphere.security.social.UserProfileManager およびcom.ibm.websphere.security.social.UserProfile API を使用して取得できます。
関連する設定:server.xml

GitHub の server.xml へのリンクはコチラ
注意:
グループ claim はデフォルトでは伝搬されないため、Azure AD の追加設定が必要です。
ID トークンにグループ claim を 追加するためには、Azure ADでタイプが「セキュリティ」のグループを作成し、1 名以上のメンバーをそのグループに追加する必要があります。
Azure AD の設定で、アプリケーションの登録時に、下記の情報を取得する必要があります。
「Token configuration」 を選択> 「Add groups claim」 を選択 >「セキュリティグループ」を選択(ID トークンを含むグループ) >「ID」を展開 > 「Customize token Properties」から「Group ID」を選択
詳細はコチラをご覧ください。
* Azure Active Directory を使用して基本グループを作成してメンバーを追加する
* グループの省略可能な要求を構成する
まとめ
このブログエントリでは、OpenID Connect と Azure Active Directory を使用してOpen Libertyアプリケーションを効果的にセキュアにする方法を示しました。
ここの記載内容に加え、オフィシャルの Azure サンプルも、WebSphere Liberty 上で簡単に動作します。
この取り組みは、Jakarta EE (Java EE)、および MicroProfile を使用する開発者に有用な情報とツールを提供するため、Microsoft と IBM が協力してできた物の一つです。
* Java EE はベンダー中立のオープンソースガバナンスの下で Jakarta EE として Eclipse Foundation に移管されました
* MicroProfileは、Java EEテクノロジーに基づいて構築され、マイクロサービスドメインを対象とする一連のオープンソース仕様です
どのようなツールやガイダンスが必要かご意見をお聞かせください。
また、特に、クラウド・マイグレーションにご興味があり、(無償で)私たちと緊密に連携したいご要望がある場合、
可能でしたら、このブログ・エントリに関する 5 分間のアンケートにご協力・ご記入頂き、貴重なフィードバックをください。
どうぞ宜しくお願いします。
Java 開発者のための Docker Multi Stage Build の活用方法
Java 開発者のために Docker Multi Stage Build を活用した本番用イメージの作成方法と、監視やデバッグが可能な検証用イメージの同時作成方法についてビデオにまとめました。どうぞご覧ください。
下記のような Multi Stage Build に対応した Dockerfile を作成します。(動画中は少し Dockerfile の書き方が変わっていますが、基本的には下記と同じです。)
# syntax = docker/dockerfile:1.0-experimental
###############################################
# Create Runtime Bases Image
###############################################
FROM mcr.microsoft.com/java/jre:11u6-zulu-alpine as base
RUN apk update \
&& apk add tzdata \
&& rm -rf /var/cache/apk/*
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP
ENV LC_ALL ja_JP.UTF-8
ENV TZ='Asia/Tokyo'
ENV APP_HOME /home/java
RUN addgroup -g 2000 -S java && adduser -u 2000 -S java -G java
USER java
WORKDIR $APP_HOME
###############################################
# Build Source Code
###############################################
FROM maven:3.6.3-jdk-11-slim as BUILD
#FROM mcr.microsoft.com/java/maven: as BUILD
WORKDIR /build
COPY pom.xml .
COPY src/ /build/src/
## Maven のローカル・レポジトリをキャッシュ
RUN --mount=type=cache,target=/root/.m2 \
mvn clean package
###############################################
# Create Final Image
###############################################
FROM base as final
COPY --from=BUILD /build/target/sample-java-app-0.0.1-SNAPSHOT.jar /home/java/app.jar
ENTRYPOINT ["java", "-jar", "/home/java/app.jar"]
EXPOSE 8080
###############################################
# Create Debuggable Monitorable Image
###############################################
FROM base as debug
COPY --from=BUILD /build/target/sample-java-app-0.0.1-SNAPSHOT.jar /home/java/app.jar
ENTRYPOINT ["java", "-Xdebug",
"-Xrunjdwp:server=y,transport=dt_socket,address=*:5050,suspend=n",
"-Dcom.sun.management.jmxremote.local.only=false",
"-Djava.rmi.server.hostname=127.0.0.1",
"-Dcom.sun.management.jmxremote",
"-Dcom.sun.management.jmxremote.port=18686",
"-Dcom.sun.management.jmxremote.rmi.port=18686",
"-Dcom.sun.management.jmxremote.authenticate=false",
"-Dcom.sun.management.jmxremote.ssl=false",
"-jar", "/home/java/app.jar"]
EXPOSE 8080 5050 18686
上記の Dockerfile を元にイメージを作成する際、それぞれ下記のようにターゲットを指定してビルドを行ってください。
本番用イメージの作成 (–target=final)
$ docker build -t tyoshio2002/spring-sample:1.0 . --target=final $ docker run -p 8080:8080 -it tyoshio2002/spring-sample:1.0
検証環境イメージの作成と起動 (–target=debug)
$ docker build -t tyoshio2002/spring-sample-debug:1.0 . --target=debug $ docker run -p 8080:8080 -p 5050:5050 -p 18686:18686 -it tyoshio2002/spring-sample-debug:1.0
その他の特記事項
上記の Dockerfile は先頭行に # syntax = docker/dockerfile:1.0-experimental と記載しています。これを記述すると Docker の Exprimental の機能 (BuildKit) が利用できるようになります。これによりビルド処理を並列で実行できるようになるほか、Dockerfile 中の下記の行のように、Multi-stage Build で Maven のローカル・レポジトリをキャッシュできるようになります。
RUN --mount=type=cache,target=/root/.m2 \
mvn clean package
より詳しく説明すると、今まではマルチステージ・ビルド中では、Maven のローカル・レポジトリをキャッシュできなかったため、ビルドの度に毎回大量の依存ライブラリをパブリック・レポジトリからダウンロードしなければなりませんでしたが、この–mount=type=cacheで毎回のダウンロードは不要になります。
こうした Docker の新しい機能もどうぞご活用ください。
Deploying Java EE apps to Azure: Part 1
この記事は Deploying Java EE apps to Azure: Part 1 の記事の日本語翻訳版です。
クラウド環境用に Java アプリケーションを開発し展開するためには下記のような様々な選択肢があります。
- IaaS(Infrastructure-as-a-Service)
- PaaS(Platform-as-a-Service)
- CaaS(Containers-as-a-Service)
- Kubernetes
- サーバーレス
- その他
上記は、いずれか一つだけを選択して使用するというよりも、それぞれに「長所と短所」があるため、利用者のニーズに応じて適材適所で組み合わせて利用することが必要です。最終的にはビジネス要件に従いどれを使用するかを決定してください。利用者にとって「選択肢」が複数あることはとても良いことです。

ここでは、Azure 上で Java EE アプリケーションを実行するための選択肢をいくつかご紹介します。
はじめに、従来のオンプレミス環境で実施していた方法と同じ手法をご紹介します。まず Microsoft Azure 上に仮想マシンを構築し、その上にアプリケーション・サーバをインストールします。そして Java EE アプリケーションをアプリケーション・サーバにデプロイします。アプリケーションはバックエンドのデータベースに接続をしますが、ここでは Azure Database for PostgreSQL をバックエンドのデータベース・サーバとして利用します。この構成は Java EE アプリケーションの構築・配備において最も典型的な構成で、本質的には IaaS(Azure VM)とPaaS(マネージドPostgreSQL on Azure)を組み合わせた構成です。
コンテナーやKubernetesなどの他の構成については、今後の投稿で取り上げます
本エントリで使用するアプリケーションのサンプルは、JAX-RS、EJB、CDI、JPA、JSF、Bean Validation など Java EE 8 の仕様に準拠した 基本的な3階層アプリケーションです。 今回 IaaS で Payara Server を構成し、バックエンドの PostgreSQL に対して接続をします。
チュートリアルは、下記の手順にしたがい行います。
- Azure 上に仮想マシンと Postgres を構築
- 仮想マシン上に Payara Server をインストール
- Java EEアプリケーションを配備
- アプリケーションの動作確認
このチュートリアルで使用するアプリケーションは一部を除いて、Reza Rahman が作成したこのプロジェクトを利用します。
前提条件
チュートリアルを実行するには、Microsoft Azure アカウントと Azure CLI が必要です。
Microsoft Azureアカウントをお持ちでない場合は、無料アカウントにサインアップしてください! Azure CLIは、Azureリソースを管理するためのクロスプラットフォームのコマンドラインエクスペリエンスです。こちらの手順に従ってインストールしてください。
最初に
Azure CLIを使用して、チュートリアルで使用する Azure のサブスクリプション ID を設定します。
AzureサブスクリプションIDを設定するには下記のコマンドを実行してください。
export AZURE_SUBSCRIPTION_ID=[to be filled] az account set --subscription $AZURE_SUBSCRIPTION_ID
次に、このチュートリアルで作成するサービス(リソース)を含むリソース・グループを作成します。
リソースグループは、Azure 上で構築する関連リソースをまとめて管理する論理的なコンテナー(ディレクトリ)のようなものです。
リソースグループを作成するために、下記のコマンドを実行してください。
export AZURE_RESOURCE_GROUP_NAME=[to be filled] export AZURE_LOCATION=[to be filled] az group create --name $AZURE_RESOURCE_GROUP_NAME ¥ --location $AZURE_LOCATION
Azure 上に PostgreSQL のインストール
Azure Database for PostgreSQL はオープンソースの Postgres データベースを利用した完全マネージドなリレーショナル・データベースサービスです。 単一サーバーもしくは、ハイパースケール(Citus)なクラスターのいずれかを選択し構築出来ます。
このチュートリアルでは、単一サーバーのオプションを選択して構築します。
Azure 上に Postgres Server のインスタンスを作成するには、az postgres server create コマンドを使用します。 まずサーバ名、管理ユーザーやパスワードなどを設定します。
export AZURE_POSTGRES_SERVER_NAME=[to be filled] export AZURE_POSTGRES_ADMIN_USER=[to be filled] export AZURE_POSTGRES_ADMIN_PASSWORD=[to be filled] export SKU=B_Gen5_1 export STORAGE=5120
ストレージとSKU で指定可能なオプションについては、こちらのドキュメントをご参照ください
下記のコマンドを実行してデータベース・インスタンスを作成します。
az postgres server create ¥ --resource-group $AZURE_RESOURCE_GROUP_NAME ¥ --name $AZURE_POSTGRES_SERVER_NAME ¥ --location $AZURE_LOCATION ¥ --admin-user $AZURE_POSTGRES_ADMIN_USER ¥ --admin-password $AZURE_POSTGRES_ADMIN_PASSWORD ¥ --storage-size $STORAGE ¥ --sku-name $SKU
コマンド実行後、構築完了まで数分かかります。しばらくお待ちください。
作成した Postgres データベースの詳細を確認するには az postgres server show コマンドを実行します。
az postgres server show ¥ --resource-group $AZURE_RESOURCE_GROUP_NAME ¥ --name $AZURE_POSTGRES_SERVER_NAME
コマンドを実行すると、JSON が表示されます。のちほど、Postgres インスタンスに接続するので、fullyQualifiedDomainName の値を書き留めてください。
[AZURE_POSTGRES_DB_NAME].postgres.database.azure.com
のように表示されています。
Azure 上に仮想マシンをインストール
Azure 上に 仮想マシン(UbuntuベースのLinux VM)を構築し、JavaEE の仕様に準拠した Payara アプリケーションサーバーをインストールします。
Linux VM の構築に必要な情報を設定します。
export AZURE_VM_NAME=[to be filled] export AZURE_VM_USER=[to be filled] export AZURE_VM_PASSWORD=[to be filled] export VM_IMAGE=UbuntuLTS
az vm create コマンドを実行して Linux VM のインスタンスを構築します
az vm create ¥ --resource-group $AZURE_RESOURCE_GROUP_NAME ¥ --name $AZURE_VM_NAME ¥ --image $VM_IMAGE ¥ --admin-username $AZURE_VM_USER ¥ --admin-password $AZURE_VM_PASSWORD
VM のプロビジョニングには数分かかりますのでしばらくお待ちください。
パブリック IP アドレスを取得するために、az vm list-ip-addresses コマンドを実行してください。
az vm list-ip-addresses ¥ --resource-group $AZURE_RESOURCE_GROUP_NAME ¥ --name $AZURE_VM_NAME
コマンドを実行すると JSON が表示されます。publicIpAddresses の箇所を確認し、ipAddress プロパティの値を確認します。
以降の手順で使用するため、環境変数に設定しておいてください。
export VM_IP=[to be filled]
Linux VM から Postgres データベースへのアクセス許可設定
Postgres データベースはデフォルトで外部からのアクセスが許可されていません。 Linux VM から Postgres インスタンスにアクセスするために、ファイアウォールでルールを追加し、アクセス許可設定を行います。az postgres server firewall-rule create コマンドを実行し、Linux VM 上にデプロイされた JavaEE アプリケーションから Postgres へ通信できるようにします。
export FIREWALL_RULE_NAME=AllowJavaEECafeAppOnVM az postgres server firewall-rule create ¥ --resource-group $AZURE_RESOURCE_GROUP_NAME ¥ --server $AZURE_POSTGRES_SERVER_NAME ¥ --name $FIREWALL_RULE_NAME ¥ --start-ip-address $VM_IP ¥ --end-ip-address $VM_IP
Linux VM へ Payara サーバのインストール
Payara Serverは、GlassFish から派生したオープンソースのアプリケーションサーバーです。オンプレミス、クラウド、ハイブリッド環境などいずれの環境でも、高信頼でセキュアな Java EE(Jakarta EE)/ MicroProfile の実行環境を提供します。
詳細については、GitHubのプロジェクトもしくはドキュメントをご参照ください。
Linux VM の IP に対してユーザ名を指定し SSH 接続します。
ssh $AZURE_VM_USER@$VM_IP
プロンプトが表示されたらパスワードを入力してください。Linux VM にログインしたのち、下記の手順を実行してください。
必要なツールセットのインストール
Payara サーバーをインストールする前に、JDK/Maven のインストールを行います。
sudo apt-get update sudo apt install openjdk-11-jdk sudo apt install maven
Payara サーバーのセットアップ
このチュートリアル執筆時点の最新の Payara サーバーのバージョンは Payara Server 5.201 です。
Payara のセットアップは、zipファイルをダウンロードして解凍するだけです。
export PAYARA_VERSION=5.201 wget https://s3-eu-west-1.amazonaws.com/payara.fish/Payara+Downloads/$PAYARA_VERSION/payara-$PAYARA_VERSION.zip sudo apt install unzip unzip payara-$PAYARA_VERSION.zip
asadmin コマンドを実行しサーバの起動
ls ~/payara5/ コマンドを実行し、インストールされたファイルやディレクトリなどのを確認してください。
次に、bin ディレクトリ下にある asadmin コマンドを使用してサーバーを起動します
ls ~/payara5/ ~/payara5/bin/asadmin start-domain
サーバーが起動するまで少し時間がかかります。 起動が完了すると下記のようなログが表示されます。
Waiting for domain1 to start ......... Successfully started the domain : domain1 domain Location: /root/payara5/glassfish/domains/domain1 Log File: /root/payara5/glassfish/domains/domain1/logs/server.log Admin Port: 4848 Command start-domain executed successfully.
アプリケーションのセットアップとデプロイ
以上で Linux VM を構築し Payara サーバをインストールし起動しました。そこでアプリケーションのデプロイを行います。
アプリケーションをデプロイするため Git リポジトリをクローンしてください。
git clone https://github.com/abhirockzz/javaee-on-azure-iaas export APP_FOLDER_NAME=javaee-on-azure-iaas
Azure の Postgres データベースに接続するために、設定ファイル中の JDBC 接続URLを更新する必要があります。
設定ファイルは、web.xmlファイル(javaee-on-azure-iaas/src/main/webapp/WEB-INF のディレクトリ下)に存在し、ファイル中の セクションの 属性を更新してください。
jdbc:postgresql://POSTGRES_FQDN:5432/postgres?user=AZURE_POSTGRES_ADMIN_USER@=AZURE_POSTGRES_SERVER_NAME&password=AZURE_POSTGRES_ADMIN_PASSWORD&sslmode=require
以下は、JDBC URL の設定項目に関するリストです。
- POSTGRES_FQDN は Postgres インスタンスが稼働するサーバの完全修飾ドメイン名を指定
- AZURE_POSTGRES_ADMIN_USER は Postgres インストール時に設定した管理者ユーザー名
- AZURE_POSTGRES_SERVER_NAME は Postgres のインストール時に設定したサーバー名
- AZURE_POSTGRES_ADMIN_PASSWORD は Postgres のインストール時に設定した管理者のパスワード
環境変数に設定します。
export POSTGRES_FQDN=[to be filled] export AZURE_POSTGRES_ADMIN_USER=[to be filled] export AZURE_POSTGRES_SERVER_NAME=[to be filled] export AZURE_POSTGRES_ADMIN_PASSWORD=[to be filled]
下記のコマンドを実行して、設定項目を修正します。
export FILE_NAME=javaee-on-azure-iaas/src/main/webapp/WEB-INF/web.xml sed -i 's/POSTGRES_FQDN/'"$POSTGRES_FQDN"'/g' $FILE_NAME sed -i 's/AZURE_POSTGRES_SERVER_NAME/'"$AZURE_POSTGRES_SERVER_NAME"'/g' $FILE_NAME sed -i 's/AZURE_POSTGRES_ADMIN_USER/'"$AZURE_POSTGRES_ADMIN_USER"'/g' $FILE_NAME sed -i 's/AZURE_POSTGRES_ADMIN_PASSWORD/'"$AZURE_POSTGRES_ADMIN_PASSWORD"'/g' $FILE_NAME
下記に セクションの例を示します。
<data-source>
<name>java:global/JavaEECafeDB</name>
<class-name>org.postgresql.ds.PGPoolingDataSource</class-name>
<url>jdbc:postgresql://foobar-pg.postgres.database.azure.com:5432/postgres?user=foobar@foobar-pg&amp;password=foobarbaz&amp;sslmode=require</url>
</data-source>
アプリケーションの設定を変更しましたので、ソースコードをビルドしましょう!
mvn clean install -f $APP_FOLDER_NAME/pom.xml
上記コマンドを実行すると、war ファイルが生成されます。下記のコマンドで war ファイルが生成されているか確認してください。
ls -lrt $APP_FOLDER_NAME/target | grep javaee-cafe.war
アプリケーション設定の最後に、Postgres の JDBC ドライバーをダウンロードして Payara サーバーに追加しましょう。
ここではドライバーのバージョンは 42.2.12 を使用しています
export PG_DRIVER_JAR=postgresql-42.2.12.jar wget https://jdbc.postgresql.org/download/$PG_DRIVER_JAR
asadmin add-library コマンドを実行し入手した jar ファイルを Payara に追加できます。
~/payara5/glassfish/bin/asadmin add-library $PG_DRIVER_JAR
もしくは、Maven の pom.xml ファイルに下記の依存関係を追加してください。
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.2.12</version>
</dependency>
最後に、WAR ファイルを Payara サーバにデプロイします。デプロイは Payara ドメインの autodeploy ディレクトリにコピーするだけでとても簡単です。
cp $APP_FOLDER_NAME/target/javaee-cafe.war ~/payara5/glassfish/domains/domain1/autodeploy
デプロイにはしばらく時間がかかりるため、それまでの間、次のコマンドでログを表示し、作業状況を確認します。
tail -f ~/payara5/glassfish/domains/domain1/logs/server.log
正常に、javaee-cafe アプリケーションのデプロイが完了すると、下記のようなメッセージが表示されます。
[2019-11-18T13:34:21.317+0000] [Payara 5.193] [INFO] [NCLS-DEPLOYMENT-02035] [javax.enterprise.system.tools.deployment.autodeploy] [tid: _ThreadID=104 _ThreadName=payara-executor-service-scheduled-task] [timeMillis: 1574084061317] [levelValue: 800] [[ [AutoDeploy] Successfully autodeployed : /home/abhishgu/payara5/glassfish/domains/domain1/autodeploy/javaee-cafe.war.]]
アプリケーションの動作確認
デプロイが完了したので、JavaEE アプリケーションの動作確認を行います。このアプリケーションは Web ブラウザーを利用してアクセスできます。しかし現時点で、Postgres のインスタンスと同様、Payara サーバーへパブリックのインターネットからは接続できません。アクセスするためには、az vm open-port を使用してファイアウォールルールを作成します。ここでは Payaraサーバーが使用するデフォルトのHTTPポート番号 8080 を公開します。
az vm open-port --port 8080 ¥ --resource-group $AZURE_RESOURCE_GROUP_NAME ¥ --name $AZURE_VM_NAME
JSF のフロントエンドにアクセス
ブラウザで http://[ENTER_VM_IP]:8080/javaee-cafe にアクセスしてください。GUIで、コーヒーの作成、削除、表示できます。
REST API の使用
このアプリケーションは、コーヒーの作成、削除、表示のための REST API も公開しています。
export VM_IP=[to be filled]
コーヒーの作成
curl -X POST $VM_IP:8080/javaee-cafe/rest/coffees ¥
-d '{"name":"cappuccino","price":"10"}' ¥
-H "Content-Type: application/json"
curl -X POST $VM_IP:8080/javaee-cafe/rest/coffees ¥
-d '{"name":"caffe-latte","price":"15"}' ¥
-H "Content-Type: application/json"
コーヒー一覧の取得
curl -H "Accept: application/json" ¥ $VM_IP:8080/javaee-cafe/rest/coffees
追加されているコーヒーのオプションのリスをを JSON で表示
ID 指定によるコーヒーの取得
curl -H "Accept: application/json" ¥ $VM_IP:8080/javaee-cafe/rest/coffees/1
ID 指定によるコーヒーの削除
curl -X DELETE $VM_IP:8080/javaee-cafe/rest/coffees/1 curl -H "Accept: application/json" ¥ $VM_IP:8080/javaee-cafe/rest/coffees
カプチーノが削除され、一覧から削除されている事を確認
リソースのクリーンアップ
アプリケーションの動作確認が完了したら、リソースを削除します。今回、リソースグループで一元管理したので、単一のコマンドを実行して削除できます。
これにより、チュートリアルの一部で作成した全リソース(VM、Postgresなど)を削除できます、ご注意ください。
az group delete --name $AZURE_RESOURCE_GROUP_NAME
まとめ
ここでは、仮想マシンにデプロイしたアプリサーバーを使用して、Java EE アプリケーションを Azure にデプロイする方法と、長期的な永続化のためにマネージド・データベースを使用する方法を学びました。
前述したように、各オプションには独自の長所と短所があります。IaaS の場合、アプリケーション、デプロイメント用のインフラストラクチャ、スケーリング方法などを完全に制御できます。一方、インフラの管理、アプリケーションのサイジング、セキュリティ保護などは、 アプリケーション機能の一部として、ご自身で責任を持たなければなりません。
次のパートでは、Dockerコンテナープラットフォームを使用してJava EEアプリケーションをデプロイする方法について説明します。 どうぞお楽しみにみしてください!
大きなファイルを 各 Pod から参照する際、DaemonSet をキャッシュとして扱う
今回とあるお客様と出会い、ハックフェストを実施した際に出てきた課題と、私からお客様に提案した対処方法が、他でも同様のニーズがあった場合に有効になるのではないかと想定し、ここにその方法を共有します。
今回のやり方にあうユースケース:
- 各 Pod から同一の巨大ファイル(GBクラスのファイル)を読み込む必要がある
- ファイルは読み込みのみで、書き込みは発生しない
(書き込みが必要な場合、別の手法で対応可能) - 巨大ファイルをできるだけ早く読み込みたい
※ ご注意:ユースケースに応じて手法は各自でご検討ください。
上記のようなユースケースの場合、DaemonSet をキャッシュとして利用する方法もご検討ください。各 Node に一つ Pod を起動する DaemonSet を利用し、DaemonSetの各 Pod にファイルのコピーを持たせます。そしてファイルを参照・取得したい Pod は、DaemonSet の Pod にあるコピー・ファイルを取得・参照する事で、ネットワークを跨いだ通信を削減できるだけでなく、ローカルでのファイル転送になるため短時間でファイルを取得できるようになります。
まぁ、普通に考えて当たり前の事を当たり前に説明しているだけなのですが。

一般的な Kubernetes での Volume のマウント方法
Kubernetes の各 Pod で永続的なボリュームを扱う際、Volume を利用して各 Pod にマウントする手法が用意されています。そして多くのクラウド・プロバイダは各クラウドのストレージ上で Persistence Volume を扱うためのプラグインを提供し、各 Pod から ストレージ内のディスクをマウントできる手法を用意しています(方法は3種類:ReadWriteOnce、ReadOnlyMany、ReadWriteMany)。
Kubernetes のドキュメントをご参照:
* Volumes
* Persistent Volumes
Azure で各 Pod からディスクを 1対1 でマウントする場合 (ReadWriteOnce)、Azure Disk を利用します。また複数の Pod から同一 Disk を共有したい場合 (ReadOnlyMany、ReadWriteMany)、Azure Files を利用します。 今回のユースケースでは、サイズの大きなファイルを複数の Pod から参照したいので、通常であれば Azure Files (ReadOnlyMany) を選択します。

具体的には、下記の手順で Azure Files を作成し、Kubernetes の Persistence Volume として Azure Files を 利用できます。
$ export AKS_PERS_STORAGE_ACCOUNT_NAME=myfilestorageaccount $ export AKS_PERS_RESOURCE_GROUP=Yoshio-Storage $ export AKS_PERS_LOCATION=japaneast $ export AKS_PERS_SHARE_NAME=aksshare $ az storage account create -n $AKS_PERS_STORAGE_ACCOUNT_NAME -g $AKS_PERS_RESOURCE_GROUP -l $AKS_PERS_LOCATION --sku Standard_LRS $ export AZURE_STORAGE_CONNECTION_STRING=`az storage account show-connection-string -n $AKS_PERS_STORAGE_ACCOUNT_NAME -g $AKS_PERS_RESOURCE_GROUP -o tsv` $ az storage share create -n $AKS_PERS_SHARE_NAME $ STORAGE_KEY=$(az storage account keys list --resource-group $AKS_PERS_RESOURCE_GROUP --account-name $AKS_PERS_STORAGE_ACCOUNT_NAME --query "[0].value" -o tsv) $ kubectl create secret generic azure-secret --from-literal=azurestorageaccountname=$AKS_PERS_STORAGE_ACCOUNT_NAME --from-literal=azurestorageaccountkey=$STORAGE_KEY
続いて、これを Pod からマウントするために volumeMounts, volumes の設定を各 Pod で行います。
apiVersion: apps/v1
kind: Deployment
metadata:
name: ubuntu
spec:
replicas: 2
selector:
matchLabels:
app: ubuntu
template:
metadata:
labels:
app: ubuntu
version: v1
spec:
containers:
- name: ubuntu
image: ubuntu
command:
- sleep
- infinity
volumeMounts:
- mountPath: "/mnt/azure"
name: volume
resources:
limits:
memory: 4000Mi
requests:
cpu: 1000m
memory: 4000Mi
env:
- name: NODE_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
volumes:
- name: volume
azureFile:
secretName: azure-secret
shareName: aksshare
readOnly: true
※ 今回ファイルサイズの大きなファイルをコピーするため4GBのメモリをアサインしています。
上記のファイルを deployment.yaml として保存し下記のコマンドを実行してください。
$ kubectl apply -f deployment.yaml
Pod が正常に起動したのち、Pod 上で mount コマンドを実行すると Azure Files が /mnt/azure にマウントされていることを確認できます。
$ kubectl exec -it ubuntu-884df4bfc-7zgkz mount |grep azure //**********.file.core.windows.net/aksshare on /mnt/azure type cifs (rw,relatime,vers=3.0,cache=strict,username=********,domain=,uid=0,noforceuid,gid=0,noforcegid,addr=40.***.***.76,file_mode=0777,dir_mode=0777,soft,persistenthandles,nounix,serverino,mapposix,rsize=1048576,wsize=1048576,echo_interval=60,actimeo=1)
この時、このファイルの実態は Azure Storage の Files Share (***************.file.core.windows.net/aksshare) 上に存在しています。

Pod から /aksshare に存在するファイルを参照する際にファイルを SMB プロトコルを利用してダウンロードします。
実際に、/mnt/azure にあるサイズの大きなファイルを Pod 内にコピーします。
# date Wed Jan 15 16:29:03 UTC 2020 # cp /mnt/azure/Kuberenetes-Operation-Demo.mov ~/mount.mov # date Wed Jan 15 16:29:54 UTC 2020 (51秒)
上記を確認すると Pod に約 3 Gb の動画ファイルをコピーするのに 51 秒ほど時間を要している事がわかります。仮に複数の Pod が起動し同一ファイルを参照した場合、ネットワークをまたいでファイルコピーが繰り返されます。これが通常の利用方法になります。
そして今回は、このファイル共有におけるネットワーク転送回数、スピードなどを DaemonSet を利用し改善します。
DaemonSet をキャッシュとして利用するための環境構築
今回、DaemonSet 上で稼働する Pod を nginx を利用して作成します。nginx のコンテキスト・ルート (/app) 配下に、Azure Blog Storage にあるファイルをコピーし、HTTP でファイルを取得できるようにします。
下記の設定により /app にあるコンテンツを http://podIP/ 経由で取得できるように設定します。
FROM alpine:3.6
RUN apk update && \
apk add --no-cache nginx
RUN apk add curl
ADD default.conf /etc/nginx/conf.d/default.conf
EXPOSE 80
RUN mkdir /app
RUN mkdir -p /run/nginx
WORKDIR /app
CMD nginx -g "daemon off;"
上記の内容を Dockerfile として保存してください。
server {
listen 80 default_server;
listen [::]:80 default_server;
root /app;
location / {
}
}
上記の内容を default.conf として保存してください。
このイメージをビルドし Azure Container Registry に Push します。
$ docker build -t tyoshio2002/nginxdatamng:1.1 . $ docker tag tyoshio2002/nginxdatamng:1.1 yoshio.azurecr.io/tyoshio2002/nginxdatamng:1.1 $ docker login -u yoshio yoshio.azurecr.io Password: $ docker push yoshio.azurecr.io/tyoshio2002/nginxdatamng:1.1
次に Kubernetes から Azure Container Registry に接続するための Secret を作成します。
kubectl create secret docker-registry docker-reg-credential --docker-server=yoshio.azurecr.io --docker-username=yoshio --docker-password="***********************" --docker-email=foo-bar@microsoft.com
Azure Container Registry にイメージを Push したので、Daemonset のマニュフェストを記述します。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: mydaemonset
labels:
app: mydaemonset
spec:
selector:
matchLabels:
name: mydaemonset
template:
metadata:
labels:
name: mydaemonset
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
imagePullSecrets:
- name: docker-reg-credential
volumes:
- name: host-pv-storage
hostPath:
path: /mnt
type: Directory
containers:
- name: nginx
image: yoshio.azurecr.io/tyoshio2002/nginxdatamng:1.1
volumeMounts:
- name: host-pv-storage
mountPath: /mnt
resources:
limits:
memory: 4000Mi
requests:
cpu: 1000m
memory: 4000Mi
lifecycle:
postStart:
exec:
command:
- sh
- -c
- "curl https://myfilestorageaccount.blob.core.windows.net/fileshare/Kuberenetes-Operation-Demo.mov -o /app/aaa.mov"
terminationGracePeriodSeconds: 30
※ 今回は検証を簡単にするため、単一ファイル (Kuberenetes-Operation-Demo.mov) を postStart のフェーズで /app 配下にダウンロードしています。複数ファイルを扱う場合、コンテナのイメージ内で複数ファイルをダウンロードする仕組みを別途実装してください。また Nginx をカスタマイズ、もしくは他の Web サーバ、App サーバを利用する事でコンテンツキャッシュを効かせるなど効率化をはかることも可能かと想定します。
上記マニュフェストファイルを daemonset.yaml として保存し、下記のコマンドを実行してください。
$ kubectl apply -f daemonset.yaml
DaemonSet を作成したのち、DaemonSet を Service として登録します。Service を作成する事で各ノードの 30001 番ポート番号にアクセスし Nginx に Node の IP アドレスとポート番号でアクセスできるようにします。
apiVersion: v1
kind: Service
metadata:
labels:
app: daemonset-service
name: daemonset-service
spec:
ports:
- port: 80
name: http
targetPort: 80
nodePort: 30001
selector:
name: mydaemonset
sessionAffinity: None
type: NodePort
上記を service.yaml として保存し、下記のコマンドを実行してください。
$ kubectl apply -f service.yaml
Nginx の DaemonSet と Ubuntu の Deployment をそれぞれ配備したのち、下記のコマンドを実行し、どのノードでどの Pod が動作しているかを確認します。
$ kubectl get no -o wide NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME aks-agentpool-41616757-vmss000000 Ready agent 176m v1.15.7 10.240.0.4 Ubuntu 16.04.6 LTS 4.15.0-1064-azure docker://3.0.8 aks-agentpool-41616757-vmss000001 Ready agent 176m v1.15.7 10.240.0.35 Ubuntu 16.04.6 LTS 4.15.0-1064-azure docker://3.0.8 aks-agentpool-41616757-vmss000002 Ready agent 176m v1.15.7 10.240.0.66 Ubuntu 16.04.6 LTS 4.15.0-1064-azure docker://3.0.8 virtual-node-aci-linux Ready agent 175m v1.14.3-vk-azure-aci-v1.1.0.1 10.240.0.48 $ kubectl get po -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES mydaemonset-gqlrw 1/1 Running 0 72m 10.240.0.24 aks-agentpool-41616757-vmss000000 mydaemonset-nnn5l 1/1 Running 0 72m 10.240.0.50 aks-agentpool-41616757-vmss000001 mydaemonset-pzvzx 1/1 Running 0 72m 10.240.0.82 aks-agentpool-41616757-vmss000002 ubuntu-884df4bfc-7zgkz 1/1 Running 0 64m 10.240.0.69 aks-agentpool-41616757-vmss000002 ubuntu-884df4bfc-gd26h 1/1 Running 0 63m 10.240.0.33 aks-agentpool-41616757-vmss000000 ubuntu-884df4bfc-vh7rg 1/1 Running 0 63m 10.240.0.49 aks-agentpool-41616757-vmss000001
上記では、ubuntu-884df4bfc-vh7rg は aks-agentpool-41616757-vmss000001 のノード上で動作しており、aks-agentpool-41616757-vmss000001 のノード上では mydaemonset-nnn5l の DaemonSet の Pod がうごしています。
そして aks-agentpool-41616757-vmss000001 のノードの IP アドレスは 10.240.0.35 である事がわかります。Ubuntu の Pod 内では Pod が稼働している Node の IP アドレスを環境変数 $NODE_IP で取得できるように設定しています。
$ kubectl exec -it ubuntu-884df4bfc-vh7rg env|grep NODE_IP NODE_IP=10.240.0.35
補足
最後に、ここでは環境構築方法の詳細説明を割愛しますが、Azure Blob Storage で Standard と Premium (高速) のそれぞれ作成し、それぞれのストレージに同一の動画ファイルを配置しておきます。
※ Azure Blob の Premium Storage は AKS の VNET と接続し VNET 経由でファイル取得しています。
その他の参考情報
* Azure Premium Storage: 高パフォーマンス用に設計する
* Troubleshoot Azure Files problems in Linux
* Troubleshoot Azure Files performance issues
検証内容
今回、下記の 4 点を検証しました。
1. Azure Files をマウントしたディレクトリに存在するファイルを Pod 内にコピーする際にかかる所用時間
2. Azure Blob (Standard) に存在するファイルを Pod で取得する際の所用時間
3. Azure Blob (Premium) に存在するファイルを Pod で取得する際の所用時間
4. DaemonSet 内にコピーしたファイルから取得する際の所用時間
1回目(実際の検証内容の動画)
下記のコマンド実行で確認しています
kubectl exec -it ubuntu-884df4bfc-vh7rg ## File Put on Azure Files (File shares : Samba) $ date $ cp /mnt/azure/Kuberenetes-Operation-Demo.mov ~/mount.mov $ date ## File Put on Azure Blob (Containers) $ curl https://myfilestorageaccount.blob.core.windows.net/fileshare/Kuberenetes-Operation-Demo.mov -o ~/direct.mov $ curl https://mypremiumstorageaccount.blob.core.windows.net/fileshare/Kuberenetes-Operation-Demo.mov -o ~/premium2.mov $ curl http://$NODE_IP:30001/aaa.mov -o ~/fromNodeIP.mov
| 回数 | PV からのコピー | Standard Storage からの入手 | Premium Storage からの入手 | DaemonSet キャッシュからの入手 |
| 1回目 | 51 秒 | 69 秒 | 27 秒 | 20 秒 |
| 2回目 | 60 秒 | 60 秒 | 23 秒 | 11 秒 |
| 3回目 | 53 秒 | 57 秒 | 20 秒 | 8 秒 |
※ ちなみに、DaemonSet の Nginx を利用した際も、初回アクセス時は時間がかかっています。これはおそらく Nginx のメモリに乗っていない為、取得に時間がかかっているように想定します。他の環境でも2回目アクセス以降は早くなっています。
検証結果のまとめ
上記、3回の実行結果より、一旦 DaemonSet にファイルを取得し、DaemonSet のキャッシュからファイルを入手するのが最も高速に入手できる事がわかりました。
Premium のストレージを利用する事で Standard のストレージよりも高速にファイル転送ができますが、Premium にすると Standard より高コストになります。また、Storage からの入手の場合、毎回ネットワークを経由してのダウンロードになる事から、それを考えても、一旦同一のノード(VM) にファイルを取ってきて、そこから入手する方が最も効率的で早い事は当たり前ですね。
DaemonSet を利用する利点
ネットワーク通信量の削減
ファイル取得スピードの高速化
DaemonSet 内のコンテナの実装を機能豊富にすれば、他にも用途が広がる(例:書き込み対応など)
懸念事項
* 現在は、特定の単一ファイルを取得していますが、複数ファイルを扱う場合、もしくはファイルの更新があった場合は、DaemonSet の内部で定期的に更新をチェックし、更新分をダウンロードする仕組みなどを実装する必要あり
* DaemonSet の Pod 内のファイルサイズが肥大化する可能性がありクリーン・アップをする必要がある
* ファイルの書き込みについては、今回の検証方法をそのまま利用した場合は対応は難しいが、DaemonSet 内のコンテナで独自に In Memory Grid 製品のような機能を実装すれば対応かと想定します。
最後に:
その他にも、内部的に検証をしたのですが、説明内容が増え視点がぼやける可能性があった為、特に効果的な点だけに絞ってまとめました。また、極力簡単にするために、DaemonSet で Nginx を使用していますが、Nginx の部分をさらにチューニングをしたり、Nginx の部分を他の実装に変更するなどで、さらなるパフォーマンス向上も見込まれるかと思います。
ぜひ、こちらの情報を元にさらなるチューニングなどを施していただければ誠に幸いです。
Azure Spring Cloud の環境構築方法のご紹介
本ブログエントリは、Microsoft Azure Advent Calendar の 20日目の内容です。
昨日は @mstakaha1113 さんによる 「AzureでIoT系のサービスをサラッと(?)使ってみよう」でした。
明日は @hoisjp さんです。
Pivotal と Microsoft は 2019/10/8 オースティンで開催された SpringOne Platform 2019 で Azure Spring Cloud というサービスを発表しました。
(SpringOne 2019 における Azure Spring Cloud の発表内容)
Azure Spring Cloud の特徴
Azure Spring Cloud は Microsoft と Pivotal が共同開発した Spring Cloud アプリケーションの開発・運用に特化した環境で、これを利用した場合、アプリケーションの運用・管理コストを大幅に軽減してくれます。
実際の実行環境は Azure Kubernets Service (AKS) ですが、Kubernetes 環境を全く意識することなく、本来必要となる複雑な管理操作を完全に隠蔽しています。実際 Kubernetes コマンドを直接実行する事はできません。その為、おそらく多くの方が Kubernetes 上で動作している事に気づかないかもしれません。
筆者は Kubernetes による Java アプリケーションの開発・運用も経験をしていますが、Kubernetes 上での開発・運用に比べて、特にインフラ面の管理コストが大幅に削減できると考えています。
通常 Kubernetes 上で Java アプリケーションを動作させるためには、コンテナを強く意識したビルド・プロセス、リリース・プロセスが必要です (コンテナのビルド、コンテナレジストリへの Push、YAML の生成、k8s への適用など)。
# Build the Source Code $ mvn clean package # Build the Container Image $ docker build -t $DOCKER_IMAGE:$VERSION . -f Dockerfile $ docker tag $DOCKER_IMAGE:$VERSION $DOCKER_REPOSITORY/$DOCKER_IMAGE:$VERSION # Push the image to Container Registry $ docker push $DOCKER_REPOSITORY/$DOCKER_IMAGE:$VERSION # Create and Modify the Deployment YAML file # Apply to the Kubernetes kubectl apply --record -f deployment.yaml
上記以外にも、Kuberenes 自身のメンテナンスやパッチ適用、クラスタ自身の運用管理を行わなければなりません。
しかし、Azure Spring Cloud を利用すると Pivotal Build Service という機能を完全統合しているため、アプリケーション開発者は、ソースコードの開発により集中できるようになります。具体的には開発者はソースコードの開発に集中し、コンテナのビルドや YAML ファイルの生成は不要で、コマンドを2、3回実行するだけで簡単にアプリケーションをデプロイできるようになります。デプロイに関しても最初から Blue-Green デプロイの機能を持つため、最新のビルドは Staging 環境にデプロイし、動作確認したのち、本番環境と切り替えるといった操作も容易に実現できます。
さらに、既存の Azure の Managed Service (現時点では Cosmos DB, MySQL, Redis) とのサービス・バインディングの機能も持つ為、JDBC などの接続情報を容易に作成することもできとても便利です。
上記以外にも多くの機能を持つ Azure Spring Cloud ですが、筆者は比較的小規模〜中規模のマイクロサービス提供をしたい場合、今後有用な選択肢になると考えています。
実際の操作イメージを掴む為、下記のデモ動画をご覧ください。
下記動画のデモ内容
- デモアプリケーションのご紹介 (PetStore)
- Azure DataBase for MySQL の動作確認
- Visual Studio Code を利用した Spring Boot アプリの実装のご紹介
- ソースコードのビルド
- Azure Spring Cloud アプリの作成
- Azure Spring Cloud アプリから Managed MySQL へのバインド
- CPU, Memory, インスタンスなどのスケール機能のご紹介
- Spring Boot アプリケーションを Azure Spring Cloud アプリへデプロイ
- Log Analytics による、アプリケーション・ログの確認
- アプリケーションの動作確認
- 分散トレーシング機能のご紹介 (Application Insights を利用)
- ブルー・グリーン・デプロイ機能の検証
ソースコード修正→ビルド→ステージング環境へのデプロイ
- ステージング・アプリと本番アプリの切り替え
- GitHub Actions を利用した CI/CD の構築
(GUI で Azure Spring Cloud と MySQL を接続する環境構築方法)
※ ご注意:本デモ動画は筆者のプレゼン時に操作時の待ち時間を短縮するため、操作待ちの箇所をカット(編集)しています。実際には、本デモ動画よりも所用時間が長くなることをご理解ください。
NeXTSTEP :Azure Spring Cloud 構築の事前準備 (CLI 版)
以降のエントリーでは、上記 GUI (動画ビデオ) で環境構築した内容と、ほぼ同等の内容を CLI (コマンドライン)だけで構築する方法について紹介します。
CLI で環境構築する場合は別途、Log Analytics や Application Insights の連携などを自ら行う必要がある為、まずはこれらを作成するところから始めます。
1. Azure へのログインと Spring Cloud 用エクステンションの追加
まず、Azure CLI を利用するために az login コマンドでログインをしましょう。そして次に、Azure Spring Cloud を操作するために、az extension コマンドでエクステンションを追加してください。
$ az login $ az extension add --name spring-cloud
2. 環境変数の設定
次に、各種リソースの名前などを可変で変更しやすくするため、さらに入力ミスを極力減らす目的で、下記の環境変数を設定してください。
$ export RESOURCE_GROUP=Spring-Cloud-Services $ export SPRING_CLOUD_SVC_NAME=spring-cloud-services-jp $ export LOCATION=southeastasia $ export APP_INSIGHTS_NAME=spring-clouds-appinsights $ export MYSQL_NAME=mysql4springcloud $ export MYSQL_USERNAME=terada $ export MYSQL_PASSWORD=whelp90-OCRs $ export MYSQL_DB_NAME=petstoredb $ export SPRING_CLOUD_APP_NAME=petstore-app $ export SPRING_CLOUD_APP_NEW_VERSION_NAME=petstore-app-new-version
上記の環境変数名のそれぞれの意味を下記に記載します。適宜ご自身の環境に応じて上記の環境変数の値は変更してください。
| 環境変数名 | 説明 |
| RESOURCE_GROUP | リソースグループ名 |
| SPRING_CLOUD_SVC_NAME | Azure Spring Cloud のサービス名 |
| LOCATION | リソースを配置するリージョンの場所 |
| APP_INSIGHTS_NAME | Application Insights の名前 |
| MYSQL_NAME | MySQL の名前 |
| MYSQL_USERNAME | MySQL のログイン・ユーザ名 |
| MYSQL_PAAWORD | MySQL のユーザ・パスワード |
| MYSQL_DB_NAME | MySQL のデータベース名 |
| SPRING_CLOUD_APP_NAME | Azure Spring Cloud のデプロイするアプリケーション名 |
| CLOUD_APP_NEW_VERSION_NAME | Azure Spring Cloud のステージング環境に配備するアプリケーション名 |
3. Azure リソースグループの作成
それでは早速、Azure Spring Cloud をインストールするリソース・グループを作成します。下記のコマンドを実行してください。
$ az group create \
--location $LOCATION \
--name $RESOURCE_GROUP
4. Application Insights のインストール
リソース・グループを作成した後、Application Insights をインストールしてください。Application Insights をインストールする事で、Azure Spring Cloud から分散トレーシング機能を利用できるようになります。
$ az resource create \
--resource-group $RESOURCE_GROUP \
--resource-type "Microsoft.Insights/components" \
--name $APP_INSIGHTS_NAME \
--location $LOCATION \
--properties '{"Application_Type":"web"}'
上記コマンドを実行した結果が、JSON 形式で出力されます。出力結果の中に、下記のような InstrumentationKey が表示されます。
後の設定で利用するため、この値をコピーして保存しておいてください。
"InstrumentationKey": "d25f6639-****-****-****-f1b******b41",
5. Log Analytics Workspace のインストール
次に、Log Analytics Workspace をインストールします。下記の defaultValue の値をご自身の環境にあわせて修正して deploy_logworkspacetemplate.json というファイル名で保存してください。
{
"$schema": "https://schema.management.azure.com/schemas/2014-04-01-preview/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"workspaceName": {
"type": "String",
"defaultValue": "workspace-name(適宜名前を修正してください)",
"metadata": {
"description": "Specifies the name of the workspace."
}
},
"location": {
"type": "String",
"allowedValues": [
"eastus",
"southeastasia",
"westus"
],
"defaultValue": "southeastasia",
"metadata": {
"description": "Specifies the location in which to create the workspace."
}
},
"sku": {
"type": "String",
"allowedValues": [
"Standalone",
"PerNode",
"PerGB2018"
],
"defaultValue": "PerGB2018",
"metadata": {
"description": "Specifies the service tier of the workspace: Standalone, PerNode, Per-GB"
}
}
},
"resources": [
{
"type": "Microsoft.OperationalInsights/workspaces",
"name": "[parameters('workspaceName')]",
"apiVersion": "2015-11-01-preview",
"location": "[parameters('location')]",
"properties": {
"sku": {
"Name": "[parameters('sku')]"
},
"features": {
"searchVersion": 1
}
}
}
]
}
上記の JSON を deploy_logworkspacetemplate.json ファイルに保存したのち、下記のコマンドを実行し Log Analytics の Workspace を作成してください。
$ az group deployment create \
--resource-group $RESOURCE_GROUP \
--name spring-cloud-log-analytics-workspace \
--template-file deploy_logworkspacetemplate.json
6. Azure Database for MySQL のインストールと検証用 DB の作成
最後の準備事項として、下記のコマンドを実行して Azure Database for MySQL をインストールします。
※ ご注意:今回の MySQL の作成方法は検証目的で作成しています。本番環境用ではないためご注意ください。
$ az mysql server create \
-l $LOCATION \
-g $RESOURCE_GROUP \
-n $MYSQL_NAME \
-u $MYSQL_USERNAME \
-p $MYSQL_PASSWORD \
--sku-name GP_Gen5_2
MySQL を作成した直後は Firewall の設定により全てのクライアントからのリクエストを受け付けられなくなっています。そこで Firewall の設定を行い MySQL に接続できるようにします。ここでは、Azure 内の IP アドレス (0.0.0.0) からだけ MySQL に接続をできるようにしています。
※ ご注意:本来は個別に接続可能な IP アドレスを設定してください。
$ az mysql server firewall-rule create \
-g $RESOURCE_GROUP \
-s $MYSQL_NAME \
-n allowfrominternal \
--start-ip-address 0.0.0.0 \
--end-ip-address 0.0.0.0
上記の設定で、Azure 内のネットワークからは MySQL に接続できるようになります。たとえばコマンドの実行環境が Cloud Shell などを利用している場合、これで接続ができるようになるかと想定します。
一方、MySQL への接続が外部のネットワークからの場合、0.0.0.0 の部分を変更し個別に接続可能な IP アドレスを指定してください。管理ポータルを利用すると簡単にクライアントの IP アドレスを入手し登録する事もできます。MySQL の「Connection Security」より「Add ClientIP」というボタンを押下するとご自身の IP アドレスが自動的に取得できます。「Save」ボタンを押下してご自身のパソコンなどからアクセスできるように設定してください。

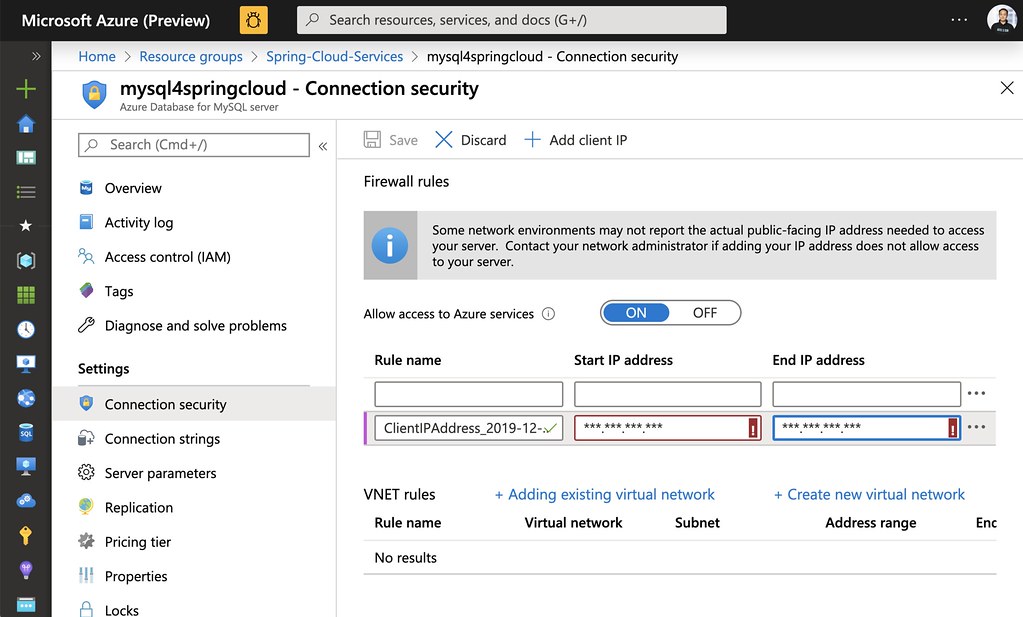
Firewall 設定が完了すると、mysql コマンドを利用して MySQL に接続ができるようになります。下記のコマンドでは日本語入力に対応する設定や、データベースの作成、さらにはテーブル作成やデータをインサートを行なっています。 ( catalog.sql は後述する git clone で入手できます)
$ mysql -u $MYSQL_USERNAME@$MYSQL_NAME \
-h $MYSQL_NAME.mysql.database.azure.com -p
mysql> show databases;
mysql> show variables like "char%";
mysql> set character_set_database=utf8mb4;
mysql> set character_set_server=utf8mb4;
mysql> create database petstoredb default character set utf8mb4;
mysql> use petstoredb;
mysql> source ./catalog.sql
mysql> select * from item;
CLI 版:Azure Spring Cloud の環境構築
7. Azure Spring Cloud の構築
上記の準備を完了することで、Azure Spring Cloud を便利に利用できるための環境が整いました。そこで、ここから実際に Azure Spring Cloud のサービスを作っていきます。リソース・グループ内に Azure Spring Cloud のサービスを作成してください。
$ az spring-cloud create \
-n $SPRING_CLOUD_SVC_NAME \
-g $RESOURCE_GROUP
8.Azure Spring Cloud と Log Analytics の連携
Azure Spring Cloud のサービスを作成したのち、Log Analytics WorkSpace と連携するための設定を行ってください。
大変残念ながら、この連携の設定は現時点で Azure 管理ポータルからしかできません。
管理ポータルから Azure Spring Cloud を選択し、「Monitoring」→「Diagnostics settings」を選択してください。

次に「+ Add diagnostic setting」を押下し「Name」に適切な名前を入力してください。

次に「Send to Log Analytics」にチェックし「Subscription」と「Log Analytics workspace」から、準備段階で作成したワークスペース名を選択してください。log, metrics の全項目にチェックし「Save」ボタンを押下してください。

以上で、デプロイしたアプリケーションのログなどが Log Analytics 経由で参照できるようになります。
9. Azure Spring Cloud 上に新規アプリの作成
Azure Spring Cloud のサービスを作成したので、次にサービス内に Spring Boot/Spring Cloud のマイクロサービス・アプリケーションをデプロイします。
$ az spring-cloud app create \
-n $SPRING_CLOUD_APP_NAME \
-s $SPRING_CLOUD_SVC_NAME \
-g $RESOURCE_GROUP
10. MySQL へのバインドを作成
次に、Azure Spring Cloud から MySQL を利用できるようにバインド設定を行います。GUI からバインドを作成する際は、GUI からサブスクリプションを選択しその中に含まれる MySQL を選択することで容易にバインド情報を作成できますが、CLI からバインドを行うためにはまず MySQL の ID を取得しなければなりません。そこで、MySQL の ID を取得するために、下記のコマンドを実行して取得してください。ここで、「“id”: “/subscriptions/***」 ではじまる行の内 「/databases/petstoredb」 より前の部分を MySQL の リソース ID (–resource-id) として利用します。
$ az mysql db show \
--name $MYSQL_DB_NAME \
-g $RESOURCE_GROUP \
--server-name $MYSQL_NAME
{
"charset": "utf8mb4",
"collation": "utf8mb4_general_ci",
"id": "/subscriptions/********-****-****-****-************/resourceGroups/Spring-Cloud-Env/providers/Microsoft.DBforMySQL/servers/mysql4springcloud/databases/petstoredb",
"name": "petstoredb",
"resourceGroup": "Spring-Cloud-Env",
"type": "Microsoft.DBforMySQL/servers/databases"
}
取得した リソース ID を指定して MySQL のバインドを作成してください。
$ az spring-cloud app binding mysql add \
--app $SPRING_CLOUD_APP_NAME \
--resource-id "/subscriptions/********-****-****-****-************/resourceGroups/Spring-Cloud-Env/providers/Microsoft.DBforMySQL/servers/mysql4springcloud" \
--database-name $MYSQL_DB_NAME \
--name "mysql-binding" \
-s $SPRING_CLOUD_SVC_NAME \
-g $RESOURCE_GROUP \
--username $MYSQL_USERNAME@$MYSQL_NAME \
--key $MYSQL_PASSWORD
バインドが完了すると Azure Portal 上では下記のような内容を確認できます。

11. サンプル・ソースコードの入手
次に、GitHub よりサンプルのソースコードやデータ、設定ファイルなどを入手してください。
$ git clone https://github.com/yoshioterada/Azure-Spring-Cloud-with-MySQL-Sample
ディレクトリ構成は下記のようになっています。
├── catalog.sql (MySQL に挿入するデータ)
├── deploy_logworkspacetemplate.json (Log Analytics Workspace を作成するためのJSON)
├── mvnw
├── mvnw.cmd
├── pom.xml
└── src
├── main
│ ├── java
│ │ └── com
│ │ └── yoshio3
│ │ └── demo
│ │ ├── CatItemRepository.java (Repository クラス)
│ │ ├── DemoApplication.java (Main クラス)
│ │ ├── Item.java (JPA Entity クラス)
│ │ └── PetItemController.java (REST API 実装クラス)
│ └── resources
│ ├── AI-Agent.xml
│ ├── application.properties
│ ├── log4j2.xml
│ ├── static
│ │ ├── css
│ │ │ ├── new-design.css (新デザイン)
│ │ │ └── old-design.css (旧デザイン)
│ │ └── images
│ └── templates
│ └── index.html ( Web ページ ThymeLeaf )
└── test
└── java
└── com
└── yoshio3
└── demo
└── DemoApplicationTests.java
12. ソースコードのビルドとアプリのデプロイ
入手したソースコードを mvn コマンドでビルドしてください。ビルドが完了すると target ディレクトリ配下に demo-0.0.1-SNAPSHOT.jar ができます。
$ mvn clean package -DskipTests $ ls target/ classes demo-0.0.1-SNAPSHOT.jar demo-0.0.1-SNAPSHOT.jar.original generated-sources generated-test-sources maven-archiver maven-status test-classes
ビルドの成果物である demo-0.0.1-SNAPSHOT.jar を Azure Spring Cloud のアプリに対してデプロイします。
この時、事前準備で作成した Application Insights の InstrumentationKey を環境変数 (–env “azure.application-insights.instrumentation-key=) に設定します。これにより Java で実装した Application Insights を動作できます。デプロイには少し時間がかかりますので、しばらくお待ちください。
$ az spring-cloud app deploy \
-n $SPRING_CLOUD_APP_NAME \
-s $SPRING_CLOUD_SVC_NAME \
-g $RESOURCE_GROUP \
--instance-count 2 --memory 2 \
--runtime-version Java_8 \
--env "azure.application-insights.instrumentation-key=********-****-****-****-************" \
--jar-path ./target/demo-0.0.1-SNAPSHOT.jar --version 1
13. 外部から接続可能な Public URL を作成
デプロイ時に Public URL の公開オプションを指定せずにデプロイすると下記のように 「Test Endpoint」しか作成されません。

GUI からは「Assign domain」のボタンを押下するだけで容易に Public URL を付加する事ができますが、CLI では下記のコマンドを実行することで Public からアクセス可能な URL を作成できます。
$ az spring-cloud app update \
-n $SPRING_CLOUD_APP_NAME \
-s $SPRING_CLOUD_SVC_NAME \
-g $RESOURCE_GROUP \
--is-public true
作成された URL を確認するために、下記のコマンドを実行してください。”url” の行に URL が表示されます。
$ az spring-cloud app show \
-n $SPRING_CLOUD_APP_NAME \
-s $SPRING_CLOUD_SVC_NAME \
-g $RESOURCE_GROUP
........ (中略)
"url": "https://spring-cloud-services-******-********-***.azuremicroservices.io"
},
"resourceGroup": "Spring-Cloud-Env",
"type": "Microsoft.AppPlatform/Spring/apps"
}
14. 動作確認
上記の URL に対して curl コマンド、もしくは Web ブラウザを利用してアクセスしてみてください。
$ curl https://spring-cloud-services-******-********-***.azuremicroservices.io/cats
15. 新バージョンをステージングへデプロイ
上記で一通りアプリケーションのデプロイはできるようになりましたが、さらにアプリケーションを更新して、Blue-Green デプロイの機能も試してみましょう。
アプリケーションの一部を更新して新バージョンを作成します。
ここではわかりやすくするため、デザインを変更してみましょう。index.html を開き、CSS を “old-design.css” から “new-design.css” に修正して、さらに <H1>Hello Java<H1> の行も追加します。
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Springboot</title>
<meta charset="utf-8" />
<link th:href="@{/css/new-design.css}" rel="stylesheet" type="text/css"></link>
</head>
<body>
<H1>Hello Java</H1>
編集が終わったのち、新しいバージョンを作るために再度 mvn コマンドでソースコードをビルドします。
$ mvn clean package -DskipTests
今回は、アプリケーションを Staging 環境にデプロイするため、下記のコマンドを実行します。–name で新規バージョンにつける名前を指定します。
(ご注意:上記で実行した az spring-cloud app deploy コマンドとは違います)
$ az spring-cloud app deployment create \
-s $SPRING_CLOUD_SVC_NAME \
-g $RESOURCE_GROUP \
--name $SPRING_CLOUD_APP_NEW_VERSION_NAME \
--version 2 \
--app $SPRING_CLOUD_APP_NAME \
--jar-path target/demo-0.0.1-SNAPSHOT.jar
16. 本番とステージングのアプリの入れ替え
上記で、Staging 環境に新しいバージョンがデプロイされましたが、新バージョンを本番環境に適用するためには、旧バージョンから新バージョンにリクエストの振り先を変える必要があります。そこで、振り先を新バージョンに変更するために下記のコマンドを実行してください。
$ az spring-cloud app set-deployment \
--deployment $SPRING_CLOUD_APP_NEW_VERSION_NAME \
--name $SPRING_CLOUD_APP_NAME \
-s $SPRING_CLOUD_SVC_NAME \
-g $RESOURCE_GROUP
このようにして簡単にバージョンの切り替えも可能です。
17. GitHub Actions による CI/CD
さらに、下記にのような GitHub Actions のワークフローを作成(.github/workflows/main.yaml)することで、GitHub に対してソースコードを Push する度に、ソースコードのビルドからデプロイまでを自動化することもできます。
このワークフローを作成する上で注意したポイントは、Staging にすでにアプリケーションがデプロイされている場合、上書きできずエラーになるため、一旦既存のデプロイ済みのアプリケーションを削除して追加しています。また、ソースコードリビジョンとデプロイ名を一致させるために、環境変数に Git のリビジョン番号などを代入し、それを名前に付加するようにしています。
name: Build and deploy on Azure Spring Cloud
on: [push]
jobs:
build-and-deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
- name: Set up JDK 1.8
uses: actions/setup-java@v1
with:
java-version: 1.8
- name: Get Year Month Day
run: echo ::set-env name=DATE::$(date '+%Y%m%d-%H%M%S')
- name: Get the Git Revision Number
run: echo ::set-env name=GIT_SHORT_VERSION::$(git rev-parse --short HEAD)
- name: Build with Maven
run: mvn package -DskipTests -Pcloud
- name: Login to Azure Spring Cloud
uses: azure/actions/login@v1
with:
creds: ${{ secrets.AZURE_CREDENTIALS }}
- name: Install Azure Spring Cloud extension
run: az extension add -y --source https://azureclitemp.blob.core.windows.net/spring-cloud/spring_cloud-0.1.0-py2.py3-none-any.whl
- name: Get Un Active Service Name
run: echo ::set-env name=UNACTIVE_SERVICE::$(az spring-cloud app deployment list -g Spring-Cloud-Services -s spring-cloud-services-jp --app petstore-app -o json | jq -c '.[]| [.name, .properties.active]' | grep false | awk -F'["]' '{print $2}')
- name: Delete UnActive Service
run: az spring-cloud app deployment delete -n ${{env.UNACTIVE_SERVICE}} -g Spring-Cloud-Services -s spring-cloud-services-jp --app petstore-app
- name: Deploy to Azure Spring Cloud
run: az spring-cloud app deployment create -g Spring-Cloud-Services -s spring-cloud-services-jp --name green-${{env.DATE}}-${{env.GIT_SHORT_VERSION}} --version ${{env.DATE}}-${{env.GIT_SHORT_VERSION}} --app petstore-app --jar-path target/demo-0.0.1-SNAPSHOT.jar
以上、で GUI でデモした内容とほぼ同等の内容を CLI だけで実施しましたが、自動化設定を行う際には本内容が必要になる場合もあるかと想定します。本エントリを少しでもお役に立てていただければ誠に幸いです。
その他の参考情報
Azure Spring Cloud は 2019 年 10 月に発表されたばかりのサービスで、現時点ではまだ Preview 版になります。しかしながら現状でも便利な機能が含まれるため、ぜひ多くの皆様にお試しいただければ誠に幸いです。また、本紙の都合上取り上げなかった機能に関しても下記のようなドキュメントから参照していただく事ができます。
Azure Spring Cloud
Azure Spring Cloud のドキュメント
その他 Spring on Azure に関する情報
Azure Spring Cloud のご紹介
また、Microsoft MVP である@setoazusaさんも、12/19 に「Azure Spring CloudでBlue-Green Deploy」というエントリーを投稿してくださっているようです。こちらも合わせてご覧ください。
さいごに
Azure Spring Cloud の正式リリース(GA) は来年 2020 年の Q2 あたりを予定しています。ご興味のある方はぜひ、お早めにお試しいただきぜひ使用感に関してフィードバックをいただければ誠に幸いです。
より多くのフィードバックをいただき改善していくことでさらに良くなってまいりますので、ぜひ多くの皆様お試しください。
ご協力のほどどうぞよろしくお願いします。
日本全国 Java & AKS (k8s) サマー・ツアー 開始
7月下旬から、8月下旬の約1ヶ月をかけて、日本全国で Java & AKS (Kubernetes) のサマー・ツアーを開始します。

既に、昨日(7月27日)、一昨日(7月28日)と仙台で Kubernetes のハッカソン・イベントを開催してきました。

今後の日本全国サマー・ツアーの予定は下記の通りです。ぜひ各地方のエンジニアの皆様どうぞお越しください。
● 仙台(7/27-7-28):https://jazug.connpass.com/event/135986/
● 札幌(7/29):https://jazug.connpass.com/event/137069/
● 東京女子部(8/3):https://jazug.connpass.com/event/137077/
● Java 女子部(8/3):https://javajo.doorkeeper.jp/events/94041
● 名古屋(8/5):https://75az.connpass.com/event/137002/
● 大阪 Day 1(8/7):https://jazug.connpass.com/event/136591/
● 大阪 Day 2(8/8):https://kanjava.connpass.com/event/139275/
● 岡山(8/10):https://okajug.doorkeeper.jp/events/94008
● 広島(8/11):https://hiroshima-jug.connpass.com/event/135650/
● 福岡(8/17-8/18):https://jazug.connpass.com/event/138372/
● 熊本(8/19):https://kumamotojava.doorkeeper.jp/events/94011
● 沖縄(8/24-8/25):https://java-kuche.doorkeeper.jp/events/94636
● 東京(8/31) : Coming Soon
皆様とお会いできるのを心より楽しみにしています。
Kubernetes の導入時に考えるべきこと
Azure にシステム導入・移行するお客様に日頃ご支援をさせていただいているのですが、多くのお客様やエンジニアの皆様から、たびたび似たようなご質問を頂くので、その内容をここに紹介したいと思います。(実際、今日もとあるお客様で下記のご相談を頂いたので)
ご質問:
お客様からたびたび頂くご質問の例
- このシステムを Kubernetes (AKS) 上で構築するのは正しいですか?
- とあるコンサルから Kubernetes を導入しないと会社の未来はないと言われたのですが、本当ですか?
- 今、Azure Web App for Container か AKS (Kubernetes) の何れかの選択で悩んでいるのですが、どちらが良いですか?
- 今、このような Kubernetes(AKS) のシステム構成を考えているのですが、正しいですか?
質問の背景:
これらのご質問は、メッセージは異なるのですが基本的には同じ質問です。結局どのような場合に kubernetes (AKS) を活用するのが効果的なのかが理解出来ていないため出てくる質問です。
個人的には当たり前になっていたので、この手の内容はまとめなくても良いかな?と思っていたのですが、度々、お問い合わせを頂くので多くの方がお悩みなのかな?と思ったのと、今日ミーティングに同席された方から、ぜひまとめて欲しいとのご要望を承ったので書くことにしました。
ご質問いただいた際の私の対応:
このようなご質問をいただく際、私からは必ず、質問者に対して下記の2つを問い合わせます。
- そのシステムは変更の激しいシステムですか?例えば今後サービスの追加は多いですか?もしくは修正が多いですか?
- コンテナ化するサービスは大量の CPU やメモリのリソースを消費しますか?
Kubernetes を選択するか否か:
A. Kubernetes が適する場合
上記の質問に対する答えに対し、1 が「はい」、2 が「いいえ」 の条件を共に満たす場合は Kubernetes の導入が適するかと思います。(前提:アジャイル、DevOps などが出来る環境が整っている会社の場合)
1: はい (変更が激しい)
2: いいえ (大量の CPU/メモリは消費しない)
B. Kubernetes が適さない場合:
一方で、上記の質問に対する答えに対し、1 が「いいえ」、2 が「はい」の条件のどちらか片方でも条件を満たす場合は、Kubernetes の導入は適さないと思います。
1: いいえ (変更は激しくない)
2: はい (大量の CPU,メモリを消費する)
理由:
システムは変更の激しいシステムか否か
まず、1 の質問の背景はマイクロサービス化をしたいと考えるお客様に対しても同様の質問をするのですが、「変更」には2つの観点があります。一つは、「既存のサービスに対し頻繁な更新・バージョン・アップ」、そしてもう一つは「新機能の追加が多くある」です。
「既存のサービスに対し頻繁な更新・バージョン・アップ」が必要な場合、一早いサービスの入れ替えが必要になります。それを実現するためには、アジャイルでの開発を実践し、DevOps でビルドやリリースのパイプラインを自動化していきます。そして、古いバージョンから新しいバージョンに安全に入れ替えるために、ローリング・アップデートやブルー・グリーン・デプロイ、カナリー・デプロイなどの手法を用いて入れ替えていく必要があります。
その際、システム構築スピードであったり、構築やサービス入れ替えの容易性が重要になってきます。デプロイ先として IaaS を選ぶ場合、VM の構築には時間が掛かります。そして上記のようなローリング・アップグレードやブルー・グリーン・デプロイ、カナリー・デプロイなどの手法を取り入れるためには、ご自身でこれらを実現するための環境を整える必要があり多大な労力を伴います。
こうした手間や労力を軽減してくれるのが PaaS (Azure では Azure Web App)であったり Kubernetes(AKS) になります。
この時点では、まだ選択肢として PaaS, Kubernetes 何れもありうる状況ですが、次に考えるのがもう一つの「新機能の追加が多くある」か否かです。デプロイするサービス数が増えて来たり、サービス間の連携などが増えてくると、PaaS では管理が煩雑になる場合があります。その場合、Kubernetes クラスター内でまとめて管理をする方がサービス間の管理やサービス全体の運用管理が楽になったり見通しが楽になったりします。
具体的なサービスの追加数は、個々のシステムや企業における運用・管理ポリシーによって異なるので本来ならば明示は避けたい所ですが、追加するサービス数が 5-10 程度ならば、迷わず PaaS をお勧めします。
しかし、サービス数が、20を超えるようならば Kubernetes の導入をお勧めします。
もちろん、 5-10 程度でも Kubernetes をご利用いただいても良いかと思いますが、導入するサービス数に対して、運用・管理、さらに学習コストの方が高くつくのではないかと想定します。
CPU やメモリのリソースを消費するか否か
また、2 の稼働させるサービスは「大量の CPU やメモリのリソースを消費しますか?」についてですが、こちらも選択する際の重要な要素と考えています。
Kubernetes 上で稼働する Pod (コンテナを束ねた物) が実際にはどこで動いているのかを考えて頂くと納得していただけるのですが、Pod(コンテナ) は、実際には、Kubernetes クラスタのノード上で動いています。ノードは実際には 1VM になります。例えば Kubernetes クラスタを 3 ノード (3 VM) で構成し、各ノードの VMに CPU 4 コア、16GB の VM を割り当てた場合を考えます。
この場合、3ノード全体で利用できる CPU やメモリーのリソースは下記の通りです。
CPU: 4 Core * 3 node = 12 Core(1200m)
Memory: 16 Gb * 3 node = 48 GB
自身が提供するサービスは、上記の 12 Core, 48 GB を超えてスケール・アウト(増やす)事は出来ません。実際には、Kubernetes を動作させるために必要な管理用の Pod(kube-system内のpod)で利用する CPU や Memory のリソースも含まれるため、上記の MAX 分までを自身のサービスを利用することも出来ません。
極端な例でわかりやすく説明すると、仮に自身が提供するサービスが 1 Pod (コンテナ) あたり CPU 1Core 分を消費するようなアプリケーションの場合、1ノードあたり 2 〜 3 Pod、トータルで 6 〜 10 pod 位しか作れないのです。また、1 Pod (コンテナ) あたり 2 GB 位メモリを消費するようなアプリの場合は、約 20 pod 位しか作れないことになります。
もし、CPU や メモリーを大量に消費するようなサービスを提供したい場合は、わざわざ Node の CPU やメモリを共有する Kubernetes 環境で提供するよりも、IaaS 環境で 1 VM に1サービスをデプロイして提供した方が、Kubernetes のオーバヘッドもなく、パフォーマンスも発揮するかと想定します。
つまり、Kubernetes で提供するサービスは、簡単にスケール・アウトしやすいサービスのデプロイには向いていますが、パフォーマンスを上げるためにスケール・アップが必要なサービスには向かないと考えています。
その場合、IaaS でも PaaS でも Serverless でも違う選択肢を考えた方が良いかと思います。
さいごに
Kubernetes は決して銀の弾丸ではないため、どうぞ適材・適所で稼働に向くサービスを稼働させるようにしてください。
Quarkus: コンテナ上で Java アプリを高速起動する新しい手法のご紹介
Docker 環境上で Java のアプリを起動するのは遅いと思っていらっしゃる方は必見!!
どうぞ下記の内容をご参照いただき、どうぞお試しください!!
先日、Red Hat から Quarkus (https://quarkus.io) という新しい技術が発表されました。こちらを実際に試して見ましたが、想定通りというか、まさにこれを待っていた!!という技術でした。今後、私の中で注目の技術の一つになりそうです。もし、Docker/k8s 上で Java アプリを動かす方は、こちらの方法をご覧いただき、ぜひ試しください。
| Quarkus を簡単にご説明すると、Java のソースコードを GraalVM を利用して Linux の Native バイナリを作成し、その Linux バイナリをコンテナ上で起動することにより、今まで Java アプリの課題であった起動時間を大幅に短縮することができる技術です。 |
※ GraalVM については、きしださんや Java Champion である阪田さんがまとめてくださっていますので、ここではその詳細説明を割愛させていただきます。
* GraalVMについて (きしださん)
* 詳説GraalVM(1) イントロダクション(阪田さん)
事前準備
- GraalVM の入手 (https://github.com/oracle/graal)
- JDK 8 以上の入手
- Maven/Gradle の入手
GraalVM を入手したのち、.bash_profile などに環境変数 GRAALVM_HOME を指定しておきます。
GRAALVM_HOME=/Library/Java/JavaVirtualMachines/graalvm-ce-1.0.0-rc13/Contents/Home export GRAALVM_HOME
それでは、実際に試して見ましょう。
1. Quarkus のクィック・スタートに従い Java のプロジェクトを作成します
$ mvn io.quarkus:quarkus-maven-plugin:0.11.0:create \
-DprojectGroupId=org.acme \
-DprojectArtifactId=getting-started \
-DclassName="org.acme.quickstart.GreetingResource" \
-Dpath="/hello"
プロジェクトを作成すると下記のようなファイルが作成されます。
├── pom.xml
└── src
├── main
│ ├── docker
│ │ └── Dockerfile
│ ├── java
│ │ └── org
│ │ └── acme
│ │ └── quickstart
│ │ └── GreetingResource.java
│ └── resources
│ └── META-INF
│ ├── microprofile-config.properties
│ └── resources
│ └── index.html
└── test
└── java
└── org
└── acme
└── quickstart
├── GreetingResourceTest.java
└── NativeGreetingResourceIT.java
2. Java のソースコードをビルドし Linux の Native バイナリを作成します
$ mvn package -Pnative -Dnative-image.docker-build=true
-Dnative-image.docker-build=true は Docker on Linux 上で実行するバイナリを生成する事を明示するオプションです。これを指定しない場合、ビルドをした環境(例えば Mac OS/X なら Mac )用のバイナリが生成されます。
2.1 作成された Linux 用のバイナリを確認します
target ディレクトリ配下に成果物ができあがります。
$ ls -l target/getting-started-1.0-SNAPSHOT-runner -rwxr-xr-x 1 yoterada staff 20112760 3 11 13:52 getting-started-1.0-SNAPSHOT-runner
2.2 file コマンドでファイル内容を確認すると Linux ELF バイナリが作成されています
$ file getting-started-1.0-SNAPSHOT-runner getting-started-1.0-SNAPSHOT-runner: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32, BuildID[sha1]=61ef9e78267993b688b9cf2de04e2aff9f1a4bfa, with debug_info, not stripped
3. Docker のビルド
Dockerfile のサンプルも下記の Dockerfile が自動的に作成されていますので、こちらをそのまま利用してビルドを行います。
17行目の COPY でビルド時に生成された Linux ELF バイナリを追加しています。
自動生成された Dockerfile
#### # Before building the docker image run: # # mvn package -Pnative -Dnative-image.docker-build=true # # Then, build the image with: # # docker build -f src/main/docker/Dockerfile -t quarkus/getting-started . # # Then run the container using: # # docker run -i --rm -p 8080:8080 quarkus/getting-started # ### FROM registry.fedoraproject.org/fedora-minimal WORKDIR /work/ COPY target/*-runner /work/application RUN chmod 775 /work EXPOSE 8080 CMD ["./application", "-Dquarkus.http.host=0.0.0.0"]
Dockerfile からコンテナ・イメージをビルドしてください。
$ docker build -f src/main/docker/Dockerfile -t tyoshi2002/quarkus-quickstart:1.0 .
4. Docker の起動
作成したコンテナ・イメージを利用してコンテナを起動します。
$ docker run -i --rm -p 8080:8080 tyoshi2002/quarkus-quickstart:1.0 2019-03-11 05:10:42,697 INFO [io.quarkus] (main) Quarkus 0.11.0 started in 0.005s. Listening on: http://0.0.0.0:8080 2019-03-11 05:10:42,699 INFO [io.quarkus] (main) Installed features: [cdi, resteasy]
私の環境では 0.005 秒で CDI+REST アプリが起動できました。
Quarkus 0.11.0 started in 0.005s. Listening on: http://0.0.0.0:8080
5. 動作確認
curl コマンド、もしくはブラウザを利用して起動したアプリケーションにアクセスします。
$ curl http://localhost:8080/hello hello
6. 備考
Quarkus は開発モード(Development Mode)も用意されており、開発時にホット・デプロイもできるようになっています。
ホット・デプロイを行うためには、下記のコマンドを実行します。
$ mvn compile quarkus:dev
こちらで起動したのち、ソースコードを修正しコンテンツを再読み込みします。
すると、再起動は不要で修正されたコードの内容を確認することができます。
7. 注意事項
Quarkus で内部的に利用されている CDI の実装 (ArC と呼ぶ) は、CDI の仕様に完全準拠しているのではなく、一部の仕様を実装したサブ・セットの実装になっています。下記にそれぞれ CDI におけるサポート、未サポートの機能についての機能一覧が説明されていますので、こちらをどうぞご確認ください。
CDI でサポートされている機能一覧
CDI で未サポートの機能一覧
8. Extension
Quarkus のアプリケーションに対して、追加のエクステンションを追加できます。追加可能なエクステンションのリストは下記から参照できます。
$ mvn quarkus:list-extensions Picked up JAVA_TOOL_OPTIONS: -Dfile.encoding=UTF-8 [INFO] Scanning for projects... [INFO] [INFO] ----------------------< org.acme:getting-started >---------------------- [INFO] Building getting-started 1.0-SNAPSHOT [INFO] --------------------------------[ jar ]--------------------------------- [INFO] [INFO] --- quarkus-maven-plugin:0.11.0:list-extensions (default-cli) @ getting-started --- [INFO] Available extensions: [INFO] * Agroal - Database connection pool (io.quarkus:quarkus-agroal) [INFO] * Arc (io.quarkus:quarkus-arc) [INFO] * AWS Lambda (io.quarkus:quarkus-amazon-lambda) [INFO] * Camel Core (io.quarkus:quarkus-camel-core) [INFO] * Camel Infinispan (io.quarkus:quarkus-camel-infinispan) [INFO] * Camel Netty4 HTTP (io.quarkus:quarkus-camel-netty4-http) [INFO] * Camel Salesforce (io.quarkus:quarkus-camel-salesforce) [INFO] * Eclipse Vert.x (io.quarkus:quarkus-vertx) [INFO] * Hibernate ORM (io.quarkus:quarkus-hibernate-orm) [INFO] * Hibernate ORM with Panache (io.quarkus:quarkus-hibernate-orm-panache) [INFO] * Hibernate Validator (io.quarkus:quarkus-hibernate-validator) [INFO] * Infinispan Client (io.quarkus:quarkus-infinispan-client) [INFO] * JDBC Driver - H2 (io.quarkus:quarkus-jdbc-h2) [INFO] * JDBC Driver - MariaDB (io.quarkus:quarkus-jdbc-mariadb) [INFO] * JDBC Driver - PostgreSQL (io.quarkus:quarkus-jdbc-postgresql) [INFO] * Kotlin (io.quarkus:quarkus-kotlin) [INFO] * Narayana JTA - Transaction manager (io.quarkus:quarkus-narayana-jta) [INFO] * RESTEasy (io.quarkus:quarkus-resteasy) [INFO] * RESTEasy - JSON-B (io.quarkus:quarkus-resteasy-jsonb) [INFO] * Scheduler (io.quarkus:quarkus-scheduler) [INFO] * Security (io.quarkus:quarkus-elytron-security) [INFO] * SmallRye Fault Tolerance (io.quarkus:quarkus-smallrye-fault-tolerance) [INFO] * SmallRye Health (io.quarkus:quarkus-smallrye-health) [INFO] * SmallRye JWT (io.quarkus:quarkus-smallrye-jwt) [INFO] * SmallRye Metrics (io.quarkus:quarkus-smallrye-metrics) [INFO] * SmallRye OpenAPI (io.quarkus:quarkus-smallrye-openapi) [INFO] * SmallRye OpenTracing (io.quarkus:quarkus-smallrye-opentracing) [INFO] * SmallRye Reactive Messaging (io.quarkus:quarkus-smallrye-reactive-messaging) [INFO] * SmallRye Reactive Messaging - Kafka Connector (io.quarkus:quarkus-smallrye-reactive-messaging-kafka) [INFO] * SmallRye Reactive Streams Operators (io.quarkus:quarkus-smallrye-reactive-streams-operators) [INFO] * SmallRye Reactive Type Converters (io.quarkus:quarkus-smallrye-reactive-type-converters) [INFO] * SmallRye REST Client (io.quarkus:quarkus-smallrye-rest-client) [INFO] * Spring DI compatibility layer (io.quarkus:quarkus-spring-di) [INFO] * Undertow (io.quarkus:quarkus-undertow) [INFO] * Undertow WebSockets (io.quarkus:quarkus-undertow-websockets) [INFO] Add an extension to your project by adding the dependency to your project or use `mvn quarkus:add-extension -Dextensions="name"` [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 1.696 s [INFO] Finished at: 2019-03-11T19:45:32+09:00 [INFO] ------------------------------------------------------------------------
上記のリストを元に、追加するエクステンションの groupId と artifactId を指定し追加ができます。
$ mvn quarkus:add-extension -Dextensions="groupId:artifactId"
例:
$ mvn quarkus:add-extension -Dextensions="io.quarkus:quarkus-smallrye-health"
9. さいごに
Quarkus は他に、CompletionStage を利用した非同期処理の実装や、JUnit のテストも REST Assured を利用して非常に書きやすくなっており、全体的にとても良くできた技術だと感じています。
ご興味ある方はぜひ、お試しください!


